前言
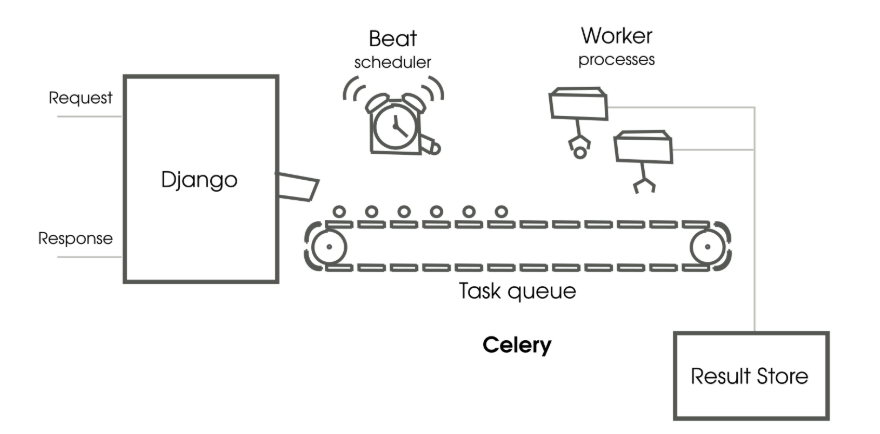
▲ 图片来源: Django Design Patterns and Best Practices - Second Edition: How Celery works
上图是一个简单的 Celery 与 Django 集成的原理示意图。
为什么需要Celery 由于单机存储过少,所以有了Hadoop;
由于磁盘计算过慢,所以有了Spark;
由于Python Web项目需要异步,所以需要引入Celery.
P.S. 写这篇文章的时候Django还是2.x的版本,而3.x的版本已经能支持异步操作了。
如果你对Kafka熟悉,那么Celery的架构也会更快理解。
Producer创建任务,任务的元(meta)信息存储到中间代理(Broker)中,再通过调度分发给不同的Celery Worker进行计算,最后把计算的结果存储到数据存储(backend)中。
Broker的选择 Celery官方推荐是使用RabbitMQ,因为 Celery的作者Ask Solem 之前惯用的就是RabbitMQ, 最早的设计也是基于RabbitMQ的。Redis是后来添加的生成环境支持Broker类型。
但是我不熟悉RabbitMQ, 为了简(tou)单(lan)起见,这里的Celery broker 选择的是Redis.
如果你已经安装好了Redis,可以直接从此处 开始阅读。
依赖
Redis 5.0.5
Python 3.6.8
Django 2.2.7
Celery 4.3.0
Redis环境准备 如果已经有Redis可以跳过以下步骤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 下载和编译 $ cd ~/installs$ wget http://download.redis.io/releases/redis-5.0.5.tar.gz $ tar -zxf redis-5.0.5.tar.gz $ cd redis-5.0.5$ make # 准备redis环境 $ mkdir ~/bin/redis-5.0.5$ ln -s ~/bin/redis-5.0.5 ~/bin/redis$ cp src/redis-server \ src/redis-cli \ src/redis-trib.rb \ redis.conf \ ~/bin/redis # 修改配置 $ cd ~/bin/redis$ vim redis.conf
Redis的配置可以按照自己的需要进行修改,这里我使用的是本地单机开发版,配置文件如下(注释部分为修改过的非默认配置)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 bind 127.0.0.1 protected-mode yes port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 300 # 允许后台运行 daemonize yes supervised no # pid文件存储在当前目录 pidfile ./redis_6379.pid # 日志级别设置为debug loglevel debug # 日志文件存储位置 logfile ./redis_6379.log databases 16 always-show-logo yes save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir ./ lazyfree-lazy-server-del no replica-lazy-flush no # 启用aof持久化策略 appendonly yes appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes aof-use-rdb-preamble yes
启动Redis
1 $ ./redis-server ./redis.conf
Celery 准备 Celery 有多个后端Broker可以选择,这里使用的是Redis,使用前需要先安装对应的Python依赖
1 2 $ pip install celery $ pip install redis
先创建一个简单的Celery app 用于验证
创建tasks.py,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 from celery import Celerybroker = 'redis://127.0.0.1:6379/0' backend = 'redis://127.0.0.1:6379/0' app = Celery('tasks' , broker=broker, backend=backend) @app.task def add (x, y ): return x + y
在同一目录下运行Celery app
1 2 3 $ celery -A tasks worker --loglevel=info ... [2019-11-11 16:31:20,114: INFO/MainProcess] celery@LAPTOP-OKN261S4 ready.
现在,我们借助Celery框架,在名为tasks的app里,定义了一个名为add的简单加法函数。
上面这么一套复杂的操作下来,就是为了能够使用异步的函数调用。
在同一目录下,启动一个Python REPL
1 2 3 4 5 6 7 8 9 10 $ python Python 3.6 .8 (default, Oct 7 2019 , 12 :59 :55 ) [GCC 8.3 .0 ] on linux Type "help" , "copyright" , "credits" or "license" for more information.>>> from tasks import add>>> result = add.delay(4 ,4 )>>> result.ready()True >>> result.get(timeout=1 )8
此时,Celery会在控制台输出类似与如下的日志
1 2 [2019-11-11 17:59:49,337: INFO/MainProcess] Received task: tasks.add[ba74cbfa-8177-4a84-9b08-e56acc4d3009] [2019-11-11 17:59:49,350: INFO/ForkPoolWorker-4] Task tasks.add[ba74cbfa-8177-4a84-9b08-e56acc4d3009] succeeded in 0.011101500000222586s: 8
同时,Redis中也会更新对应的记录
1 2 3 4 5 6 $ ~/bin/redis/redis-cli 127.0.0.1:6379> get "celery-task-meta-ba74cbfa-8177-4a84-9b08-e56acc4d3009" "{\"status\": \"SUCCESS\", \"result\": 8, \"traceback\": null, \"children\": [], \"task_id\": \"ba74cbfa-8177-4a84-9b08-e56acc4d3009\", \"date_done\": \"2019-11-11T09:59:49.339829\"}" 127.0.0.1:6379> ttl "celery-task-meta-ba74cbfa-8177-4a84-9b08-e56acc4d3009" (integer) 81858
你会发现,默认情况下,计算结果会保留一天。
你可以在官方的配置说明 中看到这个配置项result_expires
下面的示例代码中会涉及到TTL(Time to live)配置项的设置
模块集成 项目的结构如下
1 2 3 proj/__init__.py /celery.py /tasks.py
在proj/celery.py中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from celery import Celeryapp = Celery('proj' , broker='redis://127.0.0.1:6379/0' , backend='redis://127.0.0.1:6379/0' , include=['proj.tasks' ]) app.conf.update( result_expires=3600 , ) if __name__ == '__main__' : app.start()
现在已经创建好了Celery实例,也就是前面提到过的app,要使用时直接import就行。
include=['proj.tasks']只有在include中指定的模块才能被worker找到。
在proj/celery.py中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from .celery import app@app.task def add (x, y ): return x + y @app.task def mul (x, y ): return x * y @app.task def xsum (numbers ): return sum (numbers)
这里涉及到Python的一个特性,装饰器
简单来说就是引用装饰器函数的上下文(context)
使用celery -A proj worker -l info启动worker(需要在proj的上级目录)
将会出现类似于如下的输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 -------------- celery@LAPTOP-OKN261S4 v4.3.0 (rhubarb) ---- **** ----- --- * *** * -- Linux-4.4.0-17763-Microsoft-x86_64-with-Ubuntu-18.04-bionic 2019-11-12 11:18:45 -- * - **** --- - ** ---------- [config] - ** ---------- .> app: proj:0x7f2655ee5c50 - ** ---------- .> transport: redis://127.0.0.1:6379/0 - ** ---------- .> results: redis://127.0.0.1:6379/0 - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery [tasks] . proj.tasks.add . proj.tasks.mul . proj.tasks.xsum [2019-11-12 11:18:45,883: INFO/MainProcess] Connected to redis://127.0.0.1:6379/0 [2019-11-12 11:18:45,893: INFO/MainProcess] mingle: searching for neighbors [2019-11-12 11:18:46,918: INFO/MainProcess] mingle: all alone [2019-11-12 11:18:46,931: INFO/MainProcess] celery@LAPTOP-OKN261S4 ready.
这样启动的worker可以通过Ctrl + C来终止运行,但是生产环境中我们更希望能让它们在后台运行。
使用如下命令后台运行Celery实例
1 2 3 4 $ celery multi start worker1 -A proj -l info celery multi v4.3.0 (rhubarb) > Starting nodes... > worker1@LAPTOP-OKN261S4: OK
默认情况下,日志和pid文件都存在本地,假如并行度是4的情况下,会出现worker1-1.log, worker1-2.log, ……, worker1.pid存放父进程的pid。
其他控制命令如下
1 2 3 4 5 6 7 8 # 重启worker $ celery multi restart worker1 -A proj -l info # 直接停止worker $ celery multi stop worker1 -A proj -l info # 等待所有任务结束后停止worker $ celery multi stopwait worker1 -A proj -l info
可以通过启动参数设置目录和pid文件的存储位置
1 2 3 4 $ mkdir -p /var/run/celery$ mkdir -p /var/log/celery$ celery multi start worker1 -A proj -l info --pidfile=/var/run/celery/%n.pid \ --logfile=/var/log/celery/%n%I.log
更多关于celery multi的用法可以参考官方文档
如果自己设置了pid和日志的存储位置,在重启和停止时也需要指定相同的参数。
1 2 3 $ celery multi stopwait worker1 -A mark_tool -l info \ --pidfile=$projDir /var/celery/%n.pid \ --logfile=$projDir /var/celery/%n%I.log
调用任务 之前调用task中定义函数的写法:add.delay(2,2)delay另一个函数apply_async是可变参数的简写(a star-argument shortcut)的形式add.apply_async((2,2))quene1队列,在10秒后开始执行
1 add.apply_async((2 , 2 ), queue='quene1' , countdown=10 )
直接调用add函数,将会在当前进程直接执行。
详细的用法可以参见官方文档
Celery与Django集成 这里假设你已经安装 好了Python和Django
有关Django的使用,可以参考官方教程
1 2 3 4 5 6 # 初始化django项目 $ django-admin startproject celeryDemo $ cd celeryDemo# 初始化启动子应用 $ python manage.py startapp demo
在celeryDemo/setting.py中添加/修改如下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 INSTALLED_APPS = [ 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'demo.apps.DemoConfig' , ] CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0' CELERY_ACCEPT_CONTENT = ['json' ] CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0' CELERY_TASK_SERIALIZER = 'json'
这里为了方便演示,使用的是默认的SQLite数据库后端,运行如下命令在数据库中初始化对应的表
1 $ python manage.py migrate
现在我们的Django目录大致如下
1 2 3 4 5 6 7 8 9 10 11 . ├── celeryDemo │ ├── __init__.py | | │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── db.sqlite3 ├── manage.py ├── demo
创建celeryDemo/celeryDemo/celery.py,这里定义Celery实例 ,这会在之后由__init__.py加载并使用。
为什么要在这个位置创建这个名字的文件呢,这其实是一种约定,就像为啥C语言以main函数作为入口,maven的代码为啥要放在src目录下——如果不这样做,总是需要一个配置文件来指定,而配置文件的名称有需要约定,与其这样还不如直接约定好了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import osfrom celery import Celeryos.environ.setdefault('DJANGO_SETTINGS_MODULE' , 'celeryDemo.settings' ) app = Celery('celeryDemo' ) app.config_from_object('django.conf:settings' , namespace='CELERY' ) app.autodiscover_tasks() @app.task(bind=True ) def debug_task (self ): print ('Request: {0!r}' .format (self.request))
这段代码中DJANGO_SETTINGS_MODULE和app的取值需要和我们创建的项目名称celeryDemo保持一致
同时设置了所有和Celery相关的配置都要以CELERY_为前缀
这里定义了一个debug_task,中间有个Python的小语法
"Request: {0!r}" # Calls repr() on the first argument
举个例子,输出可以是
Request: <WSGIRequest: GET '/path/to/your/url'>
这段代码中,app.autodiscover_tasks()可以发现各个子Django app中定义的Celery tasks,但是对应的task需要命名为tasks.py又是万恶的约定 ,其实看函数签名,应该是可以修改成别的文件名的,
下面是部分注释和代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def autodiscover_tasks (self, packages=None , related_name='tasks' , force=False ): """Auto-discover task modules. Searches a list of packages for a "tasks.py" module (or use related_name argument). If the name is empty, this will be delegated to fix-ups (e.g., Django). For example if you have a directory layout like this: .. code-block:: text foo/__init__.py tasks.py models.py bar/__init__.py tasks.py models.py baz/__init__.py models.py """
接下来需要在celeryDemo/celeryDemo/__init__.py中导入这个Celery app
1 2 3 4 5 from .celery import app as celery_app__all__ = ('celery_app' ,)
在之前的代码中 ,我们需要先导入对应的Celery app 才能使用
而@shared_task装饰符可以使其不依赖具体的Celery app,同时能提高复用性,参见此stackoverflow问答
celeryDemo/demo/tasks.py可以写成如下形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from celery import shared_task@shared_task def add (x, y ): return x + y @shared_task def mul (x, y ): return x * y @shared_task def xsum (numbers ): return sum (numbers)
我们可以通过shell来简单验证下。
1 2 3 4 5 6 # 启动django shell $ python manage.py shell > >> from demo.tasks import add > >> res = add.delay(2,3) > >> res.status 'PENDING'
这是因为还没有启动Celery worker,所以任务还在等待队列。
这时候你能在Redis里查看对应的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 $ redis-cli -n 0 LRANGE celery 0 -1 | python -m json.tool { "body": "W1syLCAzXSwge30sIHsiY2FsbGJhY2tzIjogbnVsbCwgImVycmJhY2tzIjogbnVsbCwgImNoYWluIjogbnVsbCwgImNob3JkIjogbnVsbH1d", "content-encoding": "utf-8", "content-type": "application/json", "headers": { "lang": "py", "task": "demo.tasks.add", "id": "53d00d54-ac31-4975-9f78-76734ff0cb6a", "shadow": null, "eta": null, "expires": null, "group": null, "retries": 0, "timelimit": [ null, null ], "root_id": "53d00d54-ac31-4975-9f78-76734ff0cb6a", "parent_id": null, "argsrepr": "(2, 3)", "kwargsrepr": "{}", "origin": "gen795@LAPTOP-OKN261S4" }, "properties": { "correlation_id": "53d00d54-ac31-4975-9f78-76734ff0cb6a", "reply_to": "4a2e24b1-09a8-3fa0-a6b7-a01ee2d46fda", "delivery_mode": 2, "delivery_info": { "exchange": "", "routing_key": "celery" }, "priority": 0, "body_encoding": "base64", "delivery_tag": "aee7021b-cb54-4019-9a26-d79508a91672" } }
为了方便观察,我们在另一个shell中前台启动Celery worker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ celery -A celeryDemo worker -l info -------------- celery@LAPTOP-OKN261S4 v4.3.0 (rhubarb) ---- **** ----- --- * *** * -- Linux-4.4.0-17763-Microsoft-x86_64-with-Ubuntu-18.04-bionic 2019-11-14 11:39:36 -- * - **** --- - ** ---------- [config] - ** ---------- .> app: celeryDemo:0x7fbb0e26bfd0 - ** ---------- .> transport: redis://127.0.0.1:6379/0 - ** ---------- .> results: redis://127.0.0.1:6379/0 - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery [tasks] . celeryDemo.celery.debug_task . demo.tasks.add . demo.tasks.mul . demo.tasks.xsum [2019-11-14 11:39:36,846: INFO/MainProcess] Connected to redis://127.0.0.1:6379/0 [2019-11-14 11:39:36,856: INFO/MainProcess] mingle: searching for neighbors [2019-11-14 11:39:37,918: INFO/MainProcess] mingle: all alone [2019-11-14 11:39:37,936: INFO/MainProcess] celery@LAPTOP-OKN261S4 ready. [2019-11-14 11:39:37,941: INFO/MainProcess] Received task: demo.tasks.add[53d00d54-ac31-4975-9f78-76734ff0cb6a] [2019-11-14 11:39:37,956: INFO/ForkPoolWorker-4] Task demo.tasks.add[53d00d54-ac31-4975-9f78-76734ff0cb6a] succeeded in 0.010209599997324403s: 5
此时Python中REPL
1 2 3 4 5 6 >>> res.task_id'53d00d54-ac31-4975-9f78-76734ff0cb6a' >>> res.status'SUCCESS' >>> res.get()5
Redis
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 队列中的任务已经完成 $ redis-cli -n 0 LRANGE celery 0 -1 (empty list or set) # 计算结果 $ redis-cli -n 0 GET celery-task-meta-53d00d54-ac31-4975-9f78-76734ff0cb6a | python -m json.tool { "status": "SUCCESS", "result": 5, "traceback": null, "children": [], "task_id": "53d00d54-ac31-4975-9f78-76734ff0cb6a", "date_done": "2019-11-14T11:39:37.946697" }
模拟真实场景 假设一个这样的场景:
用户填写表单,数据传入后台时需要做一段时间的计算才能返回结果,这时候可以先返回,
计算结果通过回调函数来传回页面
警告 : 以下内容不适合那些幽默感退化的人们进行阅读
用户通过页面填写一个整数,点击上传到服务器上进行,来进行云计算,将结果乘上2返回。
但是呢,我们的网络由于后端微服务太多,调用过程就需要消耗5秒,我们的服务器由于超卖,CPU占满了,导致计算结果太慢了,要花费5秒才能算完。
假如在等待的过程中阻塞住了用户的行为(跳转换成别的界面就看不了结果了),
非得等10秒计算完才能进行下一步操作,那么计算3个整数至少要30秒。
除了上面的问题外,还有别的问题。用户等不及算完一个还得等着结果才能算下一个,想要算完一个就返回一个,边算边提交,算完的结果立刻就能看,这就是所见即所得
Django本身(2.2版本)是不支持这一操作的,但是有了Celery就不一样了。
有了Cooooool的Celery,我们就能把任务放到后台运行,计算结果完成后,由函数式编程语言javascript来提供展示和页面的更新。
为了更好地进行说明,记录以下几个时间
EventTime 用户提交表单的时间
ProcessingTime 表单数据被放入Celery Task 开始运行的时间
FinishTime Celery Task 计算完成的时间
此处略过Django项目的初始化和子项目的创建过程
celeryDemo/demo/tasks.py
1 2 3 4 5 6 7 8 9 10 11 12 13 from celery import shared_taskfrom datetime import datetime, timezone, timedeltafrom time import sleep@shared_task def double_a_integer (n, event_time ): processing_time = datetime.utcnow().replace(tzinfo=timezone.utc) \ .astimezone(timezone(timedelta(hours=8 ))) sleep(5 ) finish_time = datetime.utcnow().replace(tzinfo=timezone.utc) \ .astimezone(timezone(timedelta(hours=8 ))) return event_time, processing_time, finish_time, 2 * n
这里的FinishTime其实用AsyncResult(task_id).date_done更加准确,前者由于任务还没有完全关闭,比后者早了约0.08ms,这里没有选后者,是为了展示起来格式上统一都带上时区。
为了方便用户进行人性化的操作体验 ,我们需要添加个按钮
哦,对了,为了展示数据,还需要有个表格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <form method ="post" action ="{% url 'demo:calc' %}" > {% csrf_token %} <label for ="single" > Input a integer </label > <input type ="text" name ="number" placeholder ="32" id ="number" > <button id ="b01" type ="button" onclick ="get_result($('#number'))" class ="btn btn-lg btn-danger " style ="height:35px;width:100px;font-size:14px" > OK </button > </form > <table class ="table" style ="visibility:hidden" id ="table" > <thead > <tr > <th > task id</th > <th > event time</th > <th > process time</th > <th > finish time</th > <th > result</th > </tr > </thead > <tbody > </tbody > </table >
不要问我为什么界面那么难看,你去问 前端/美工/UI设计 啊
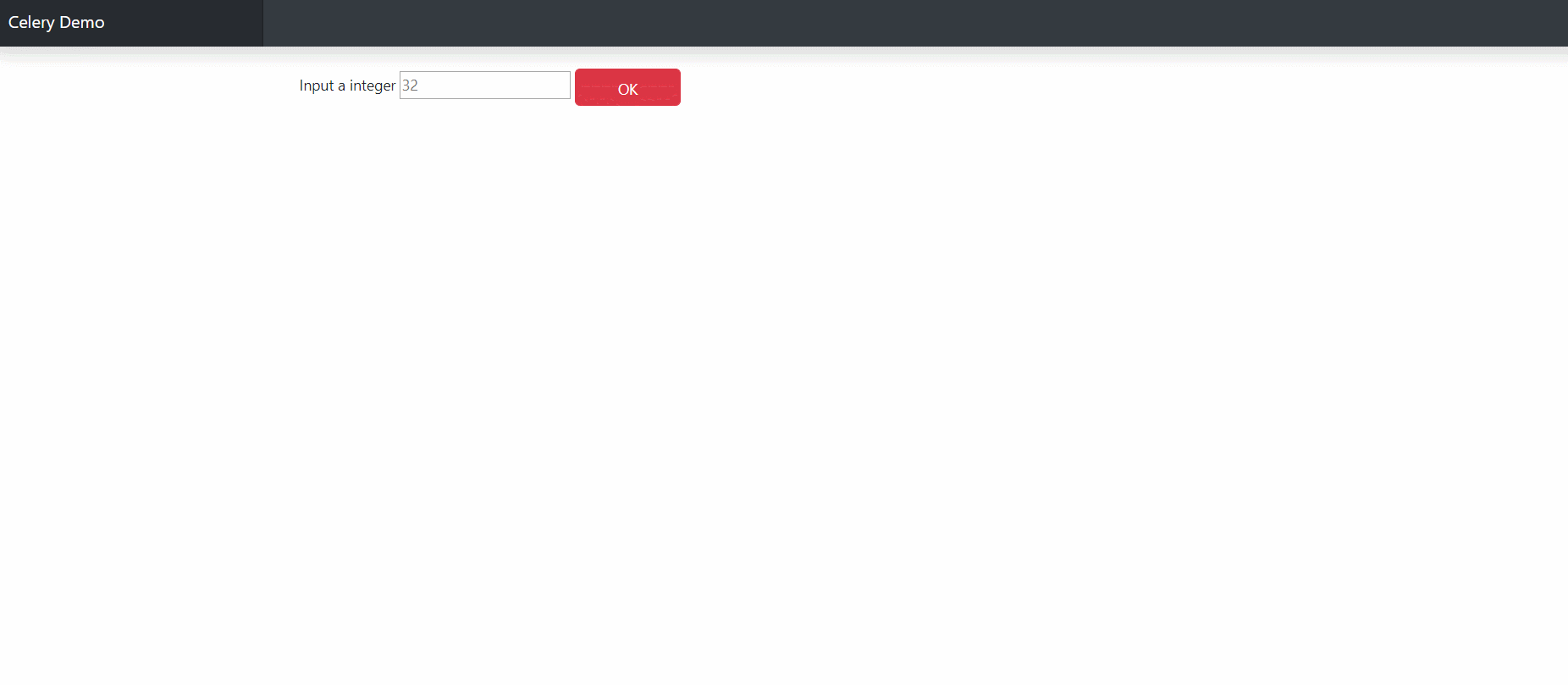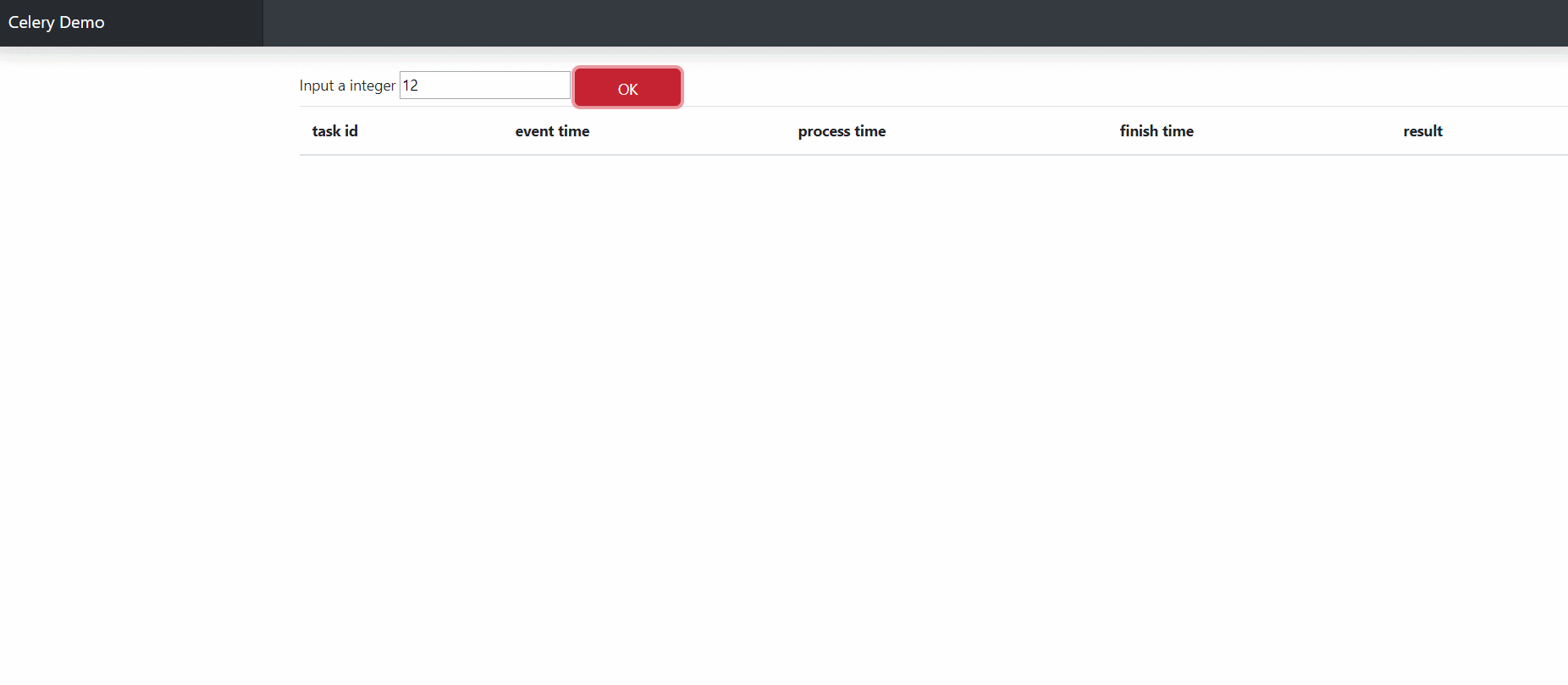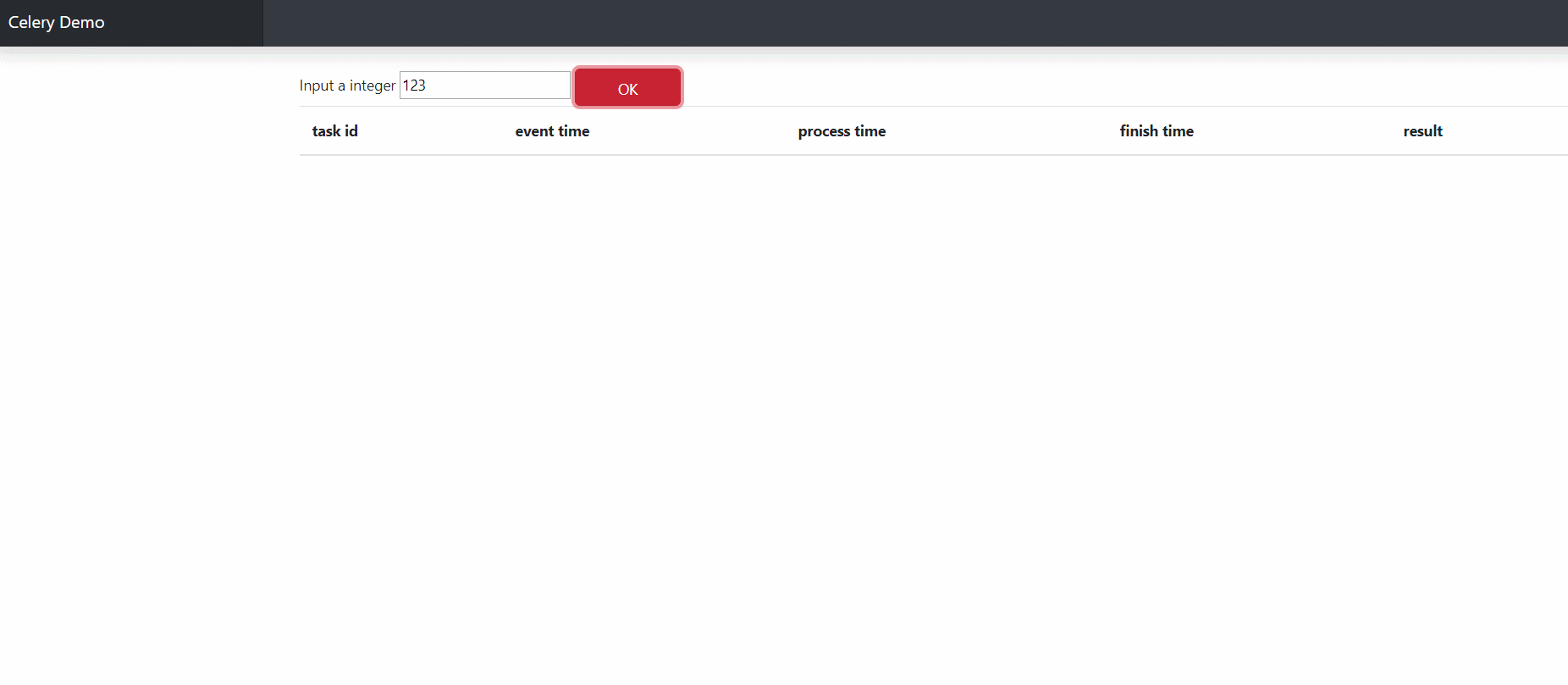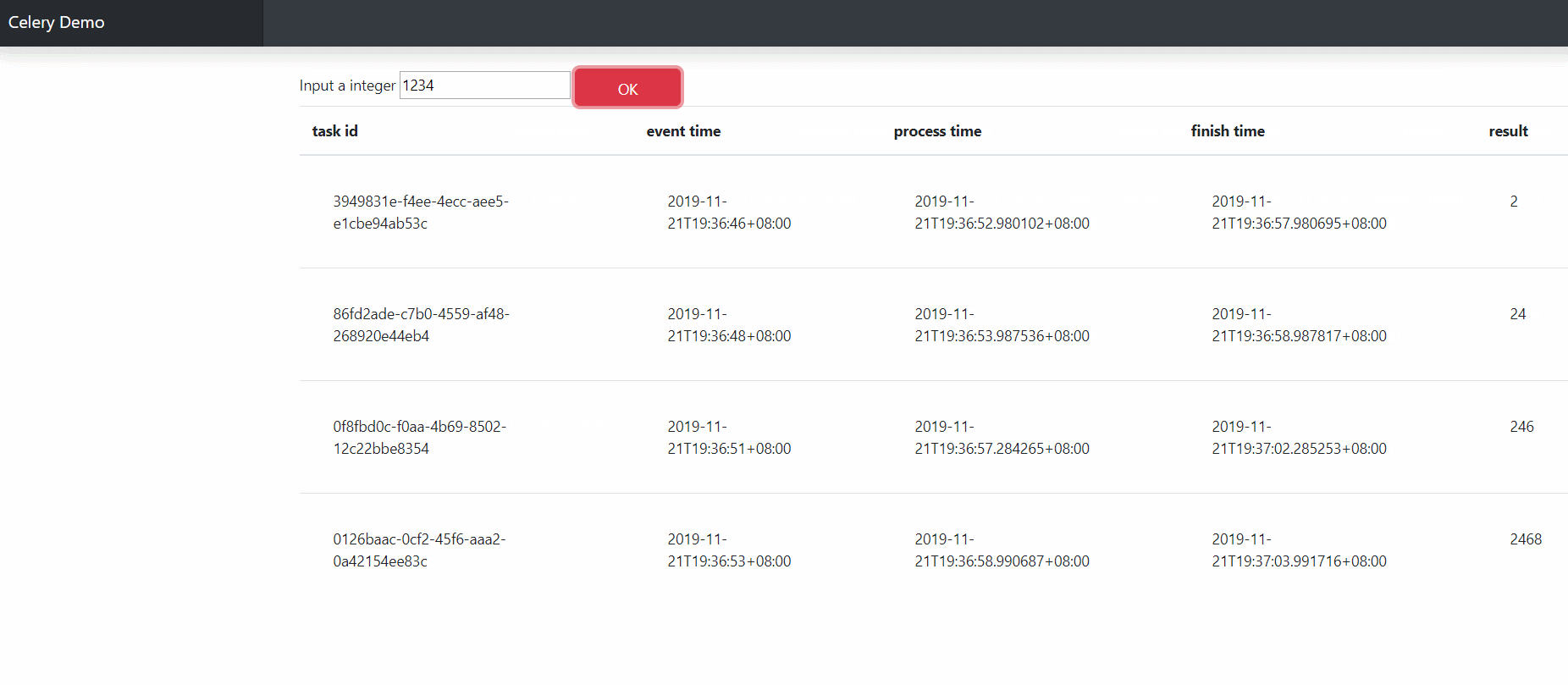
上面的点击按钮会触发js中的函数,获取对应的Celery task ID, 使用这个ID轮询服务器任务状态,
完成时更新对应表格内容。
demo/static/js/index.js
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 let u_calc = $("#u_calc" ).attr ("data-url" );let u_check = $("#u_check" ).attr ("data-url" );function getCookie (name ) { let cookieValue = null ; if (document .cookie && document .cookie !== '' ) { let cookies = document .cookie .split (';' ); for (let i = 0 ; i < cookies.length ; i++) { let cookie = cookies[i].trim (); if (cookie.substring (0 , name.length + 1 ) === (name + '=' )) { cookieValue = decodeURIComponent (cookie.substring (name.length + 1 )); break ; } } } return cookieValue; } let csrf_token = getCookie ('csrftoken' );function csrfSafeMethod (method ) { return (/^(GET|HEAD|OPTIONS|TRACE)$/ .test (method)); } function listenToTask (task_id ) { let runningTaskNumber = 1 ; document .getElementById ('table' ).style .visibility = 'visible' ; console .log (task_id); let insertRow = function (data ) { let row = "<tr>\ <td><div class='card-body'>" + data.task_id + "</div></td>\ <td><div class='card-body'>" + data.eventTime + "</div></td>\ <td><div class='card-body'>" + data.processingTime + "</div></td>\ <td><div class='card-body'>" + data.finishTime + "</div></td>\ <td><div class='card-body'>" + data.result + "</div></td>\ </tr>" ; $('#table tr:last' ).after (row); }; let poll = function ( $.ajax ({ beforeSend : function (xhr, settings ) { if (!csrfSafeMethod (settings.type ) && !this .crossDomain ) { xhr.setRequestHeader ("X-CSRFToken" , csrf_token); } }, method : "GET" , type : "GET" , url : u_check + "?task_id=" + task_id, async : true , dataType : "json" , contentType : "application/json" , success : function (data ) { if (data.status === "SUCCESS" ) { runningTaskNumber -= 1 ; insertRow (data); } else { console .log (data.status ); } }, }); }; let check = function ( let refresh = setInterval (function ( if (runningTaskNumber === 0 ) { clearInterval (refresh); } else { poll (); } }, 1000 ) }; if (runningTaskNumber > 0 ) check (); } function get_result (number ) { let n = number.val (); if (n.length === 0 ) { alert ("please input a integer before submit." ) } else if (!n.match (/^\d+$/ )) { alert (n + " is not a valid integer." ); } else { $.ajax ({ beforeSend : function (xhr, settings ) { if (!csrfSafeMethod (settings.type ) && !this .crossDomain ) { xhr.setRequestHeader ("X-CSRFToken" , csrf_token); } }, method : "POST" , type : "POST" , url : u_calc, async : true , dataType : "json" , data : JSON .stringify ({'number' : n, 'eventTime' : new Date ().toUTCString ()}), contentType : "application/json" , success : function (data ) { listenToTask (data.task_id ); }, }); } }
完成时结果如下图所示,是不是如丝般顺滑
项目的完整代码放在此处
UPDATE1:
参考: https://flower.readthedocs.io/en/latest/install.html
当任务过多时,我们希望能监控任务的状态,有个比较常见的组件flower可以满足这一需求。
1 2 $ pip install flower $ celery flower --port=5555 --broker=redis://localhost:6379/0
用了下感觉有点鸡肋
也许是我没找到正确的使用姿势?
参考资料
Redis 下载 Celery 官网 Celery: Getting Start Celery User Guide: Tasks Celery: Next Setps Django: Getting Start Django Design Patterns and Best Practices - Second Edition: How Celery works 知乎专栏: 使用Celery Celery + Redis 的探究 异步任务队列Celery在Django中的使用 关于django集成celery 听说 Django 与 celery 配合更美味 Github: ctudoudou/celery-demo Github: sunshineatnoon/Django-Celery-Example StackOverflow: Using Ajax with celery task StackOverflow: Js Date object to python datetime StackOverflow: Update Django model object once Celery task is complete W3school: HTML DOM clearInterval() 方法 Celery Doc Flower: Real-time Celery web-monitor