年终碎碎念和来年Flag
夫天地者,万物之逆旅也;光阴者,百代之过客也。—— 李白《春夜宴从弟桃花园序》
博客一周年(2018-11-20 ~ 2019-12-31), 之后如果还有总结,就直接以自然年为周期了
关于博客
过去的一年里,我一共写了42篇博客。
你问我怎么统计的?ls hexo/source/_posts | wc -l站内统计用的是Google Analytics,中间有段时间搞错了配置文件,部分数据没有统计上。
总访客数量为1516
| 流量来源 | 占比 |
|---|---|
| Organic Search | 52.9% |
| Direct | 32.4% |
| Referral | 14.2% |
| Social | 0.5% |
主要的流量来自Google搜索。
社交部分的流量来自于FaceBook的链接分享(但是我搜不到对应的链接
奇怪的是引用部分的流量,明明没有提交网页链接,但最多的流量来自于百度
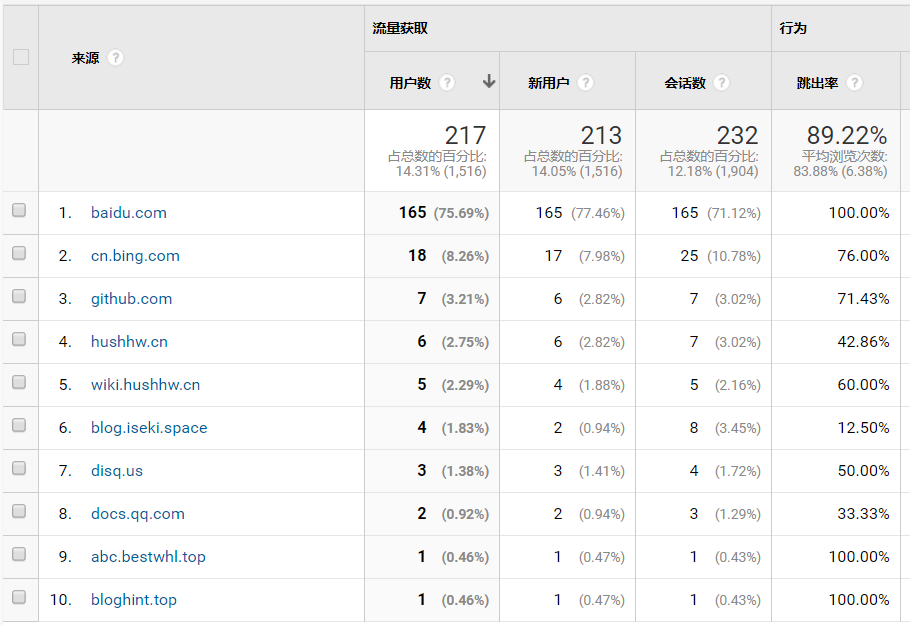
我很好奇使用什么keyword搜进来的,我自己搜都进不来。
没有找到该URL。您可以直接访问 counter2015.com,还可提交网址给我们。
以下是网页中包含”counter2015.com”的结果:
接着是Bing(But is not Google),和github个人主页,以及交互友链的博主们(嗯,有两个了,可以用复数来形容)
再往下就是其他不(shan)知(zhai)名的搜索引擎了
访问量top10(按照独立访客数量统计)
Prometheus + Grafana 监控配置指北:打造日志监控系统
虽然说步骤算是比较详细了,但是2022年,能使用容器化部署的情况下比手动部署更加方便。比如说使用 k8s 的 grafana operator
-
微软家大业大,看来是不会像国内厂商一样禁止图片外链。目前也没有看到禁止用户将图片存放到 github repo 的用户条款
Kafka HDFS Sink Connector 简单使用
水文
-
水文
-
influxDB 用作监控时序数据的存储,2022年看来还是一个比较主流的选择
-
水文
-
时代的眼泪
Scala Puzzle 5.The Missing List
回过头来看的时候,发现很多细节我都记不清了。现在 Scala 3 已经发布,可能有些内容也需要修订
-
水文
-
水文
说起来浏览量最高的是Prometheus的博客可是我不是运维呀
写这篇博客的时候,其实是因为原来旧版的监控页面用起来太难(chou)了(一个简单用echars画的界面,而程序员的设计审美嘛,你懂的),想换一个更好(zhuang)看(bi)的界面来统计下后台TPS和响应时间。
然后就开始收集资料,最开始是想用Zabbix做数据源,Grafana做可视化,后来发现Zabbix不好装,换成了Prometheus。
在Go的群里问有没有相关教程,被当成伸手党。
“原来还提供手把手服务啊”
嗨,被嘲讽了,那就自己动手呗
折腾了半天,最后统计响应时间,使用Mtail来解析日志。
mtailworks best when it paired with a timeseries-based calculator and alerting tool, like Prometheus.So what you do is you take the metrics from the log files and you bring them down to the monitoring system?
It deals with the instrumentation so the engineers don’t have to! It has the extraction skills! It is good at dealing with log files!!
复杂的业务逻辑自己写了个Scala 的 Exporter来统计日志中的信息
不同日志的切换策略不同又是一个坑,有的是直接mv走,有的是改软链,还有的直接把历史文件打包。文件的监听部分是Mtail帮忙做的,部分是自己用Crontab监听Inode来做的。
Prometheus配置的节点一多,配置文件就不好改了,得用脚本生成的半自动方式来改(好蠢)
现在用起来是监控了100+机器的指标,包括TPS,响应时间,机器的监控指标(CPU,负载,带宽等),这得感谢Grafana有足够多的模板,很多sql只要拿过来改改就能用。
其他
在GA面板上,我观察到了这么两个请求
1 | /translate_c?depth=1&hl=en&prev=search&rurl=translate.google.com&sl=zh-CN&sp=nmt4&u=https://counter2015.com/2019/04/30/grafana-moniter/&xid=17259,15700023,15700186,15700190,15700256,15700259&usg=ALkJrhgIQ0NFH3n_3nLmbxGb3oxLFzctMQ |
看来是有人通过谷歌翻译,
查看英文版的Grafana监控和日文版的Giter8介绍
Across the Great Wall
we can reach every corner in the world .
居然有歪果仁能看到,运气不错啊
读过的书
推荐自己没读过的书就是在耍流氓。
《Spark 快速大数据分析》 通读,一如既往的OREILLY风格,是不是还要查下看
《Copying and pasteing from stackoverflow》 简短得让你看到封面时以为这本书是恶搞的
《面向对象葵花宝典》 通读,生动活泼的方法论书籍
《Code: the hidden language of computer hardware and software》 弃读,感觉在讲电路硬件,标题欺诈
《大数据技术原理与应用 》通读,原理方面有了实践经验后来看更好吸收,但是内容有些过时了
《人月神话》 跳读,终于明白了人月代表的含义和“没有银弹”的出处(问:怀孕需要10个月,10个孕妇能不能在一个月内生出一个小孩)

以下的书正在读,还没读完
- 《Scalatra in Action》精读 一个较小众的Scala Web框架,同位置下多采用Play?(虽然我现在用的是Django
- 《Scala puzzlers》 精读,中英对照着看,中文翻译存在错漏,缺少原文幽默的风味,发现自己姿势水平不够,重新看基础
- 《Programming in Scala》 精读, 边看边做笔记,目前看到了23章For循环
- 《Spark: The Definitive Guide》精读,刚开始看开头,开ACM会员,免费读Orelly精品电子书(此条5毛,括号内删除) 话说都快出3.0了
- 《Function Programming in Scala》 精读,也称小红书,做完了前两章的习题
- 《Scala with Cats》 精读,还没开始读,不过这个封面真好看啊

碎碎念
读文档的时候发现的,这翻译,我上我也行
这在只有两个字段时显得没啥卵用,但对于拥有数十个字段的表单来说,为表单选择一个直观的排序方法就显得你的针很细了。 —— Django Doc: https://docs.djangoproject.com/zh-hans/2.2/intro/tutorial07/
Django文档写的是真的好
日常黑js
1 | > 'b' + 'a' + + 'a' + 'a' + 's' |
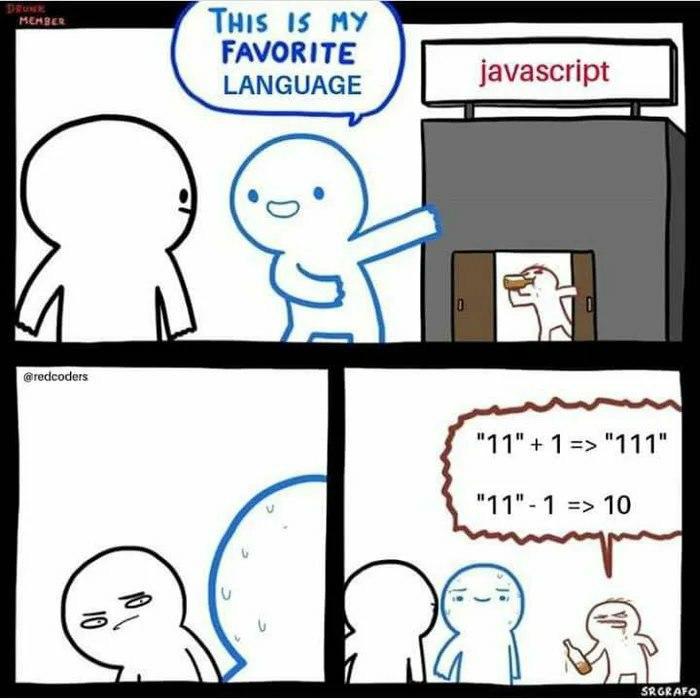
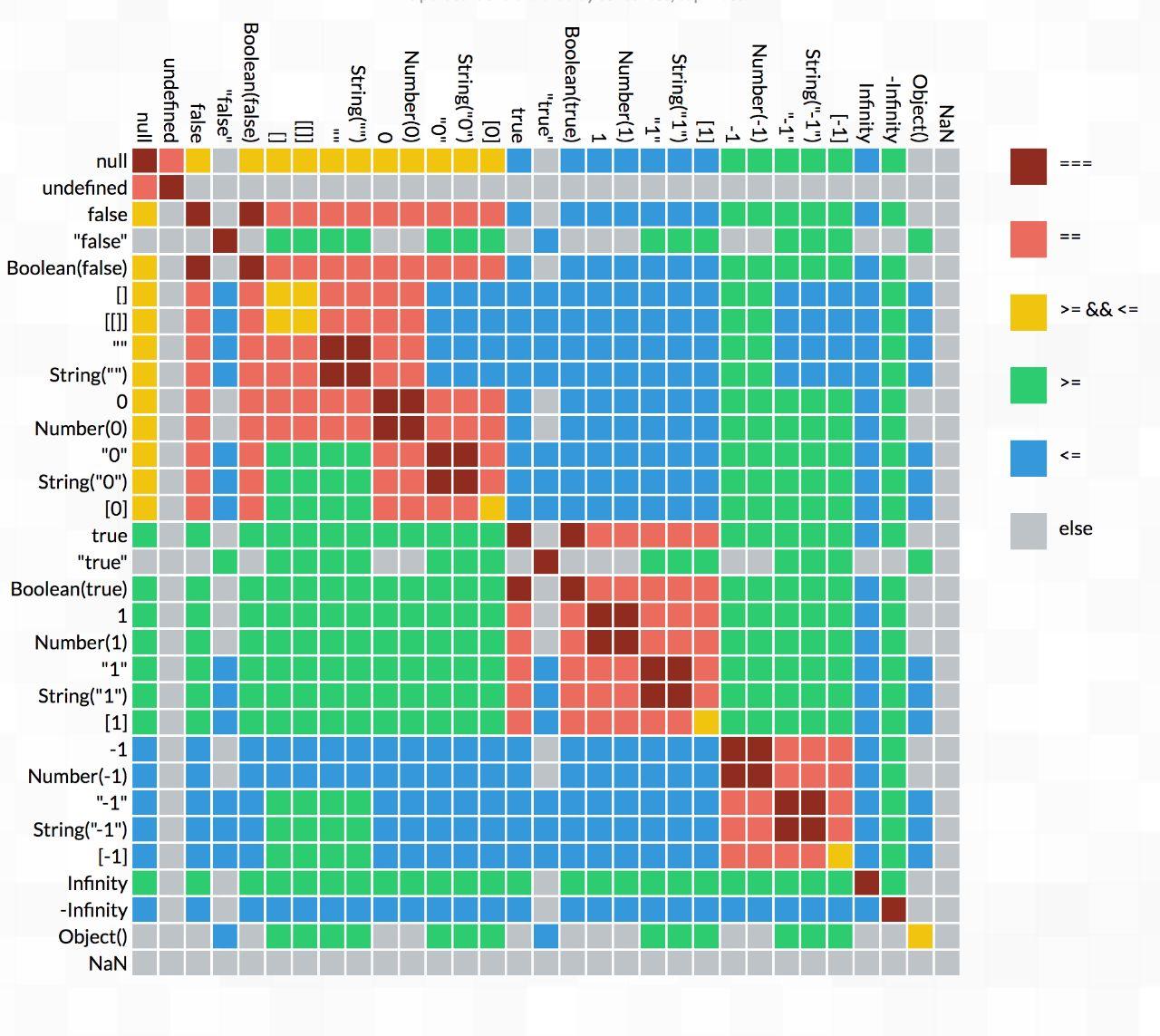
骚操作
- MySQL里存HTML页面
- 普通的陕西普通话官网
航天精神
特别能吃苦、特别能战斗、特别能攻关、特别能奉献
我只能做到前20%,”特别能吃”
弃捐勿复道,努力加餐饭
有一句话叫GIGO(Garbage In Garbage Out),二手知识虽然容易消化些,但是一手的消息是最吼的,所以写博客的时候,我会尽可能多地表明参考文章,官方文档(锅不在我这,别往我这甩)
开源软件的版本更新是很快的,有时候写下的内容不适用于新版,所以我尽可能多标注版本号和平台环境。正如之前说的,
文字一旦被记录下来,就开始老化,纸上的文字只能承载过去的看法,不断地思考,比任何经典更为鲜活
过去的一年学到了什么
- 大数据相关组件 Hadoop, HDFS, Yarn, Flume, Zookeeper, Kafka, Spark, Flink, Hive, HBase的
拼写和基本认知,简单流式计算和RDD编程,简单组件的搭建运维 - Github基本交流和Issues,PR的使用,Hello World级别的CI/CD
- 编码规范,单元测试的编写
- 在高级攻城狮的指导下进行搬砖
- Python Web编程开发基础
- Linux环境下基本命令的使用
- Bug驱动的搜索引擎使用方法论
- 按照丹方使用自己的数据进行炼丹的经验
- 搭积木
新年Flag
去年的计划完成情况就是这样了
新的一年,又有新的Flag
读书笔记
-
给Scala Puzzles 填坑 5/? -
学习Scalatra 8/? - 完成Coursera 上的Scala课程
-
给博客添加一言(hitokoto)完善LeetCode-Scala项目
阅读谷三篇论文
系统学习Spark五年计划:持续学习这个项目里感兴趣的课程
学习做菜
- 煮饭
- 蛋炒饭

- 辣椒炒白菜
- 土豆炒香肠

- 香肠炒豆干
- 鸡蛋煮面
- 煎饺子煮饺子和
炒饺子 - 鸡蛋煎饺

- 蛋挞

- 炒粉

剩下的想到了再写
版权声明:
除另有声明外,本博客文章均采用 知识共享(Creative Commons) 署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议 进行许可。
分享