# my global config global: scrape_interval:15s# Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval:15s# Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml"
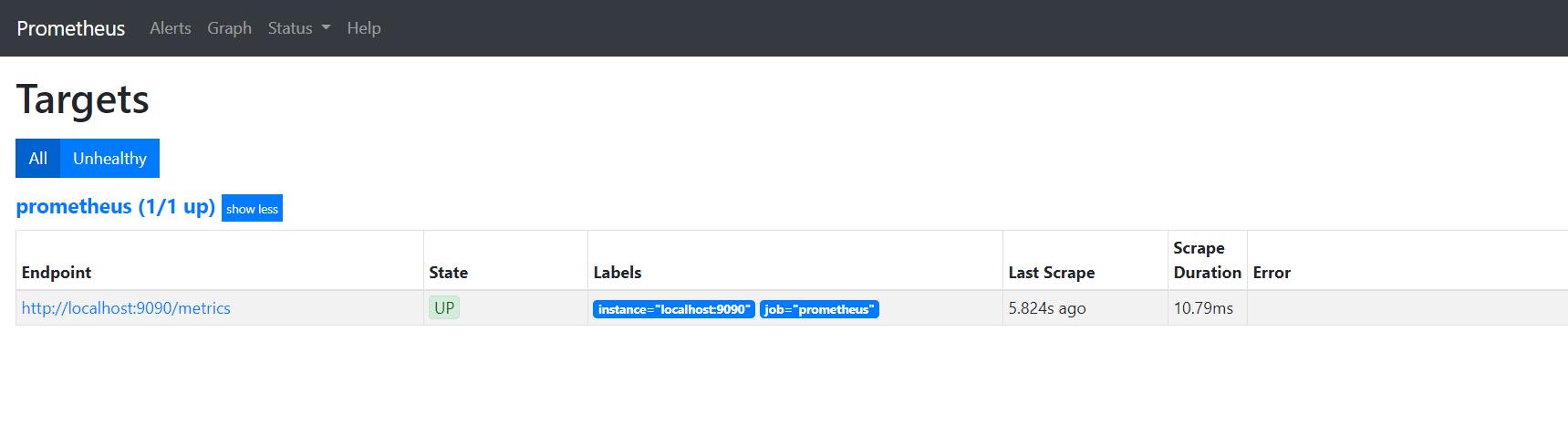
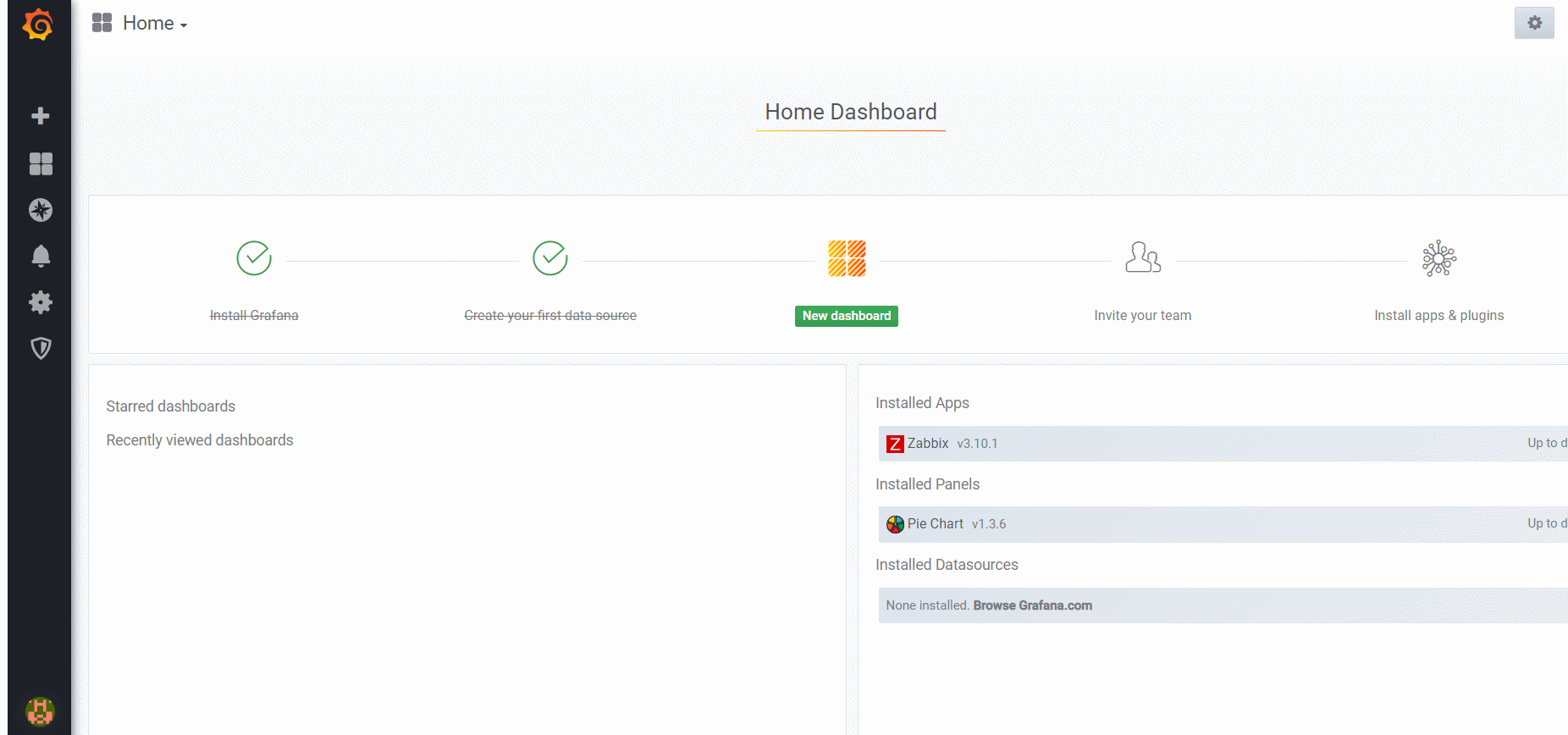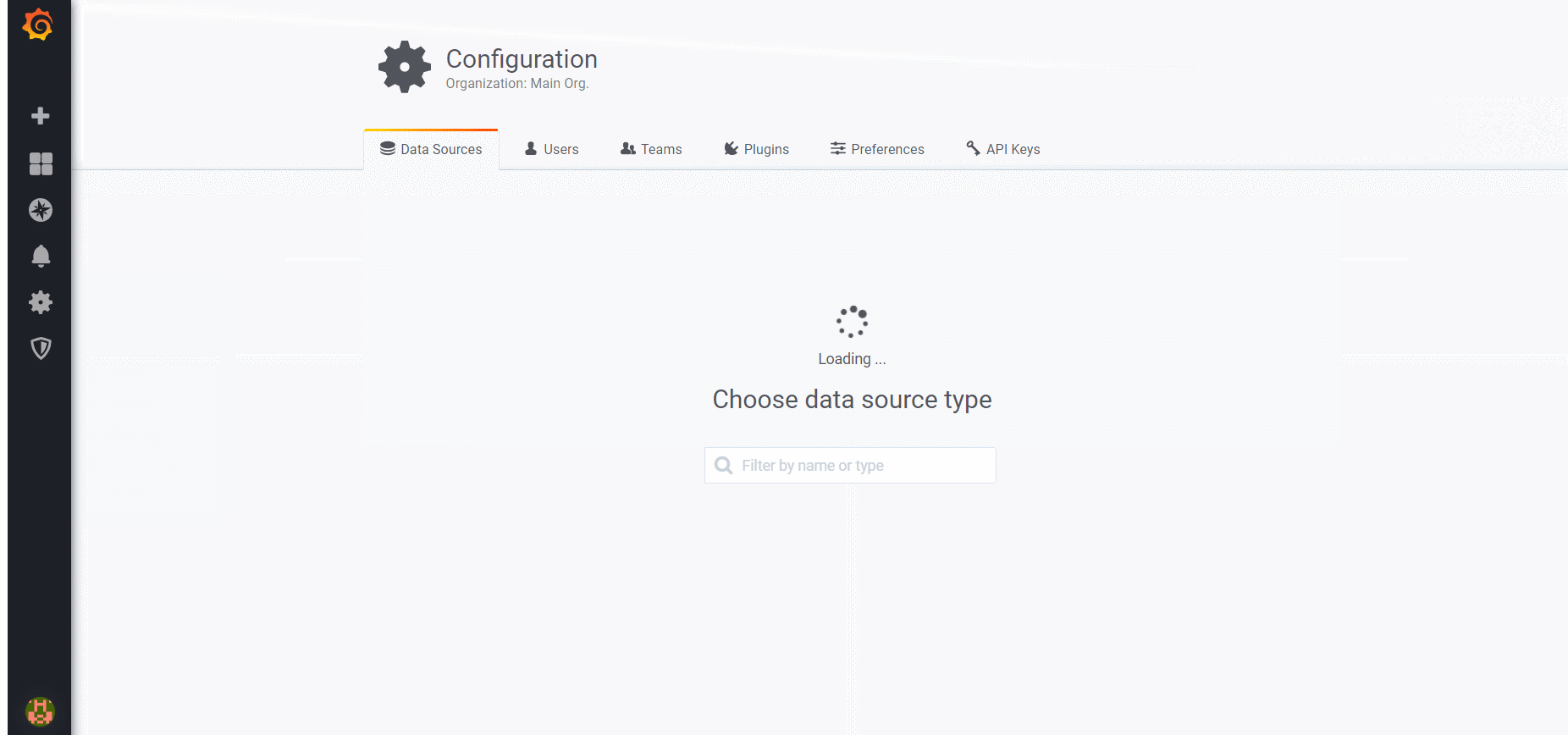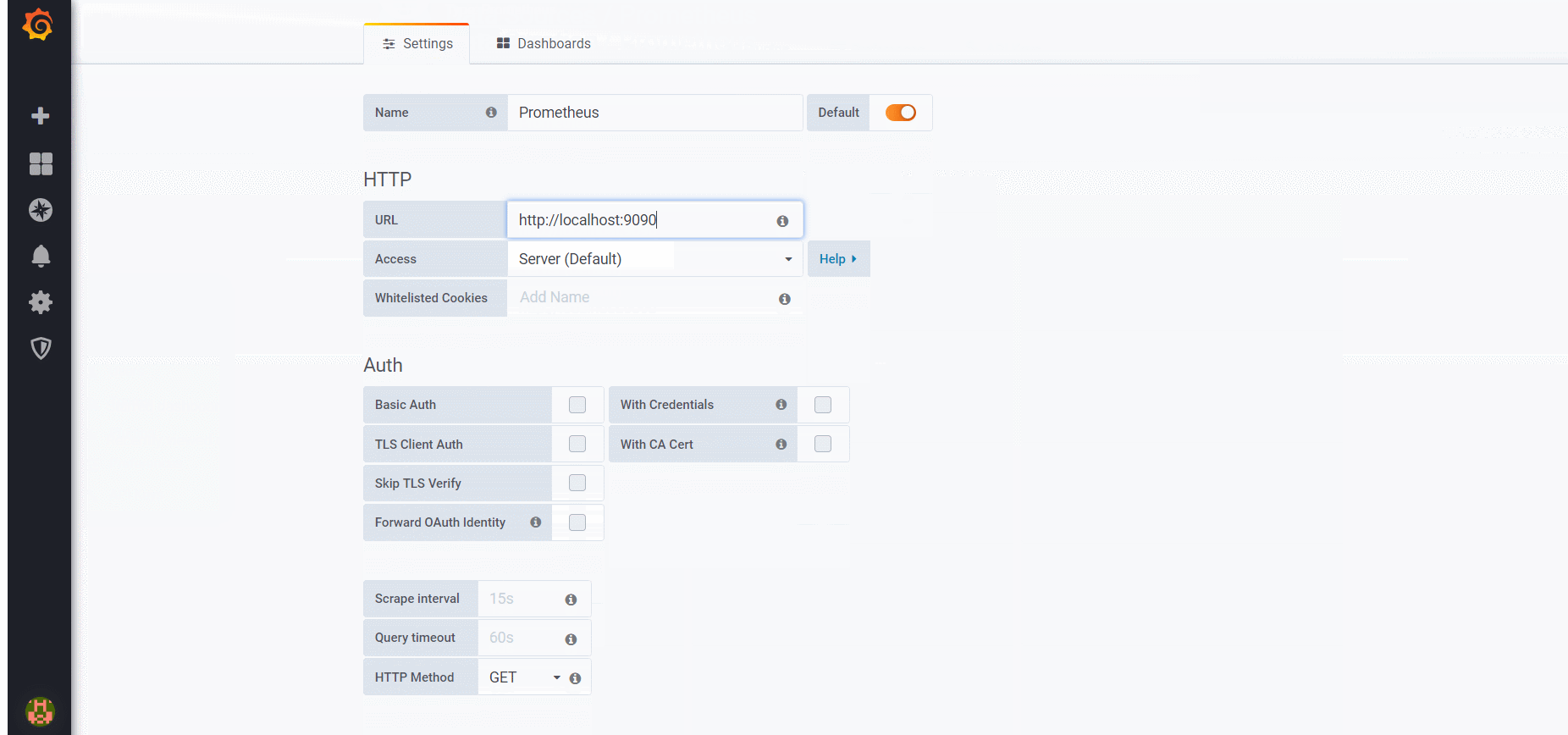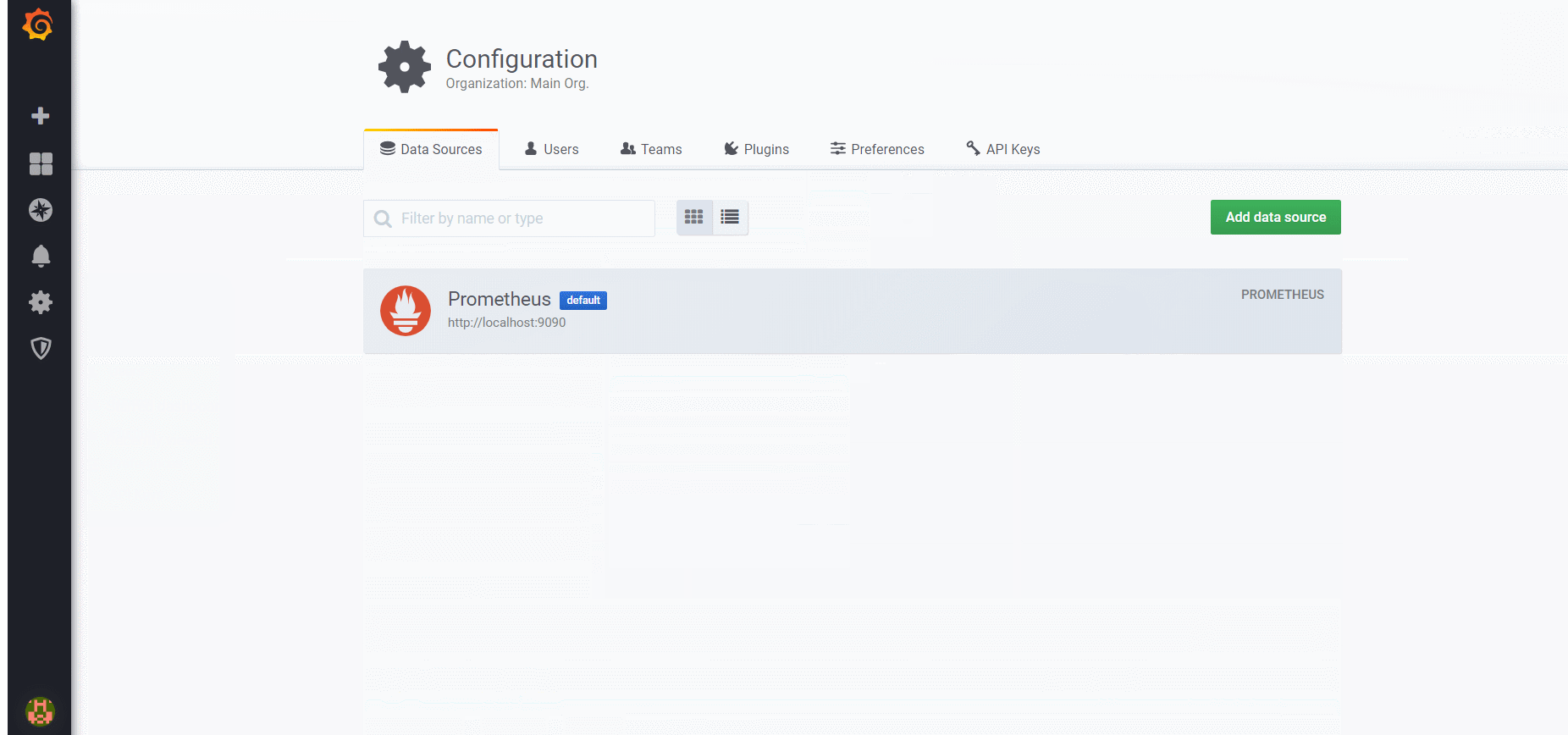
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. -job_name:'prometheus'
# metrics_path defaults to '/metrics' # scheme defaults to 'http'.
$ sudo vim /etc/influxdb/influxdb.conf # Bind address to use for the RPC service for backup and restore. bind-address = "10.1.2.3:8088" $ sudo systemctl restart influxdb
$ influxd restore -portable -db prometheus -newdb prometheus_bak /tmp/influxdb-backup2 $ influx > use prometheus_bak > SELECT * INTO prometheus..:MEASUREMENT FROM /.*/ WHERE time>'2020-04-07T06:01:00Z' and time <'2020-04-13T07:59:00Z' GROUP BY *
假如是全新的配置,不需要导入历史数据的情况下的话,需要创建对应数据库
1 2 3 4 5 6 7 8 9 10
$ influx -precision rfc3339 Connected to http://localhost:8086 version 1.7.10 InfluxDB shell version: 1.7.10 > CREATE DATABASE "prometheus" > SHOW DATABASES name: databases name ---- _internal prometheus
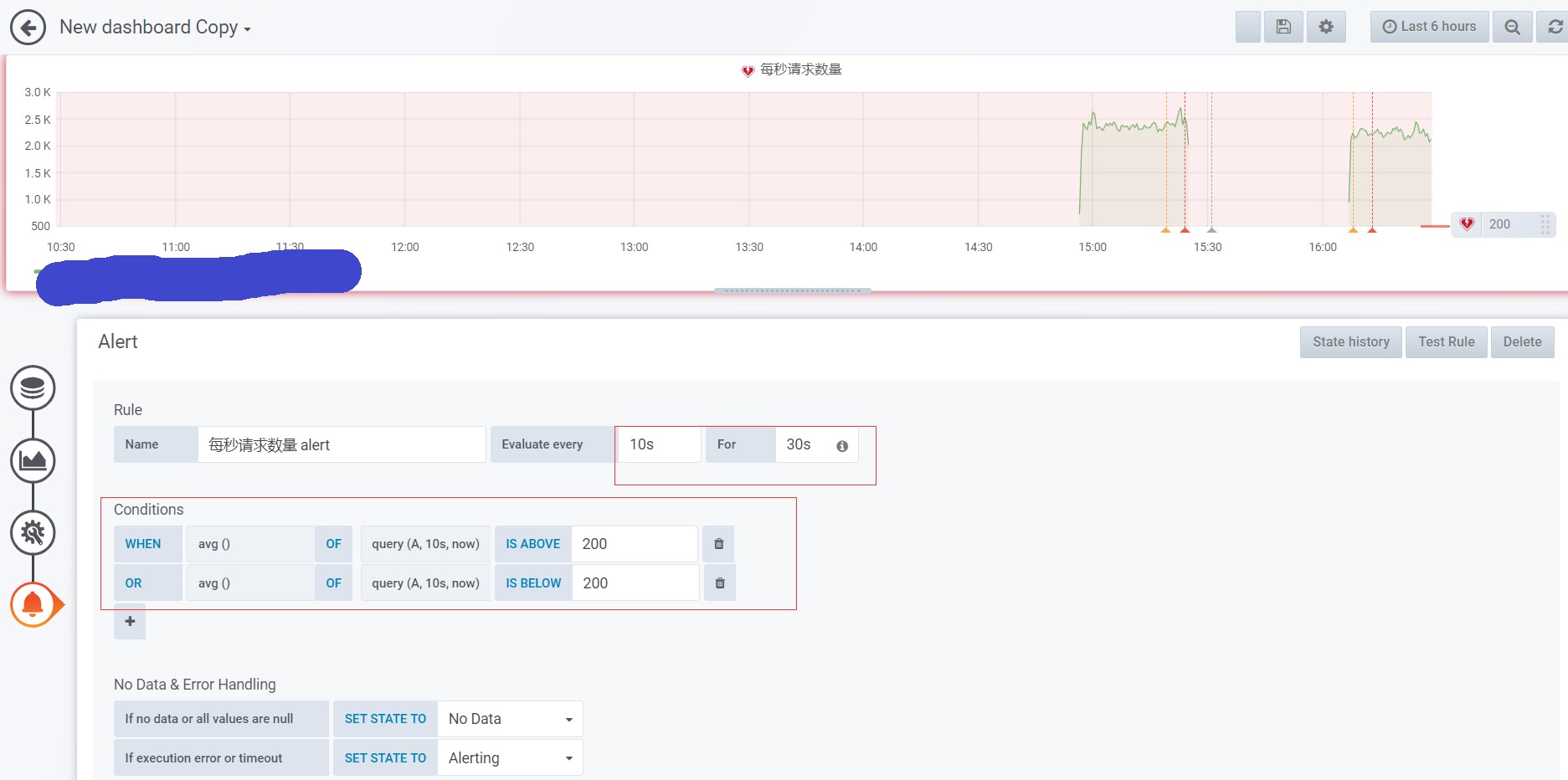
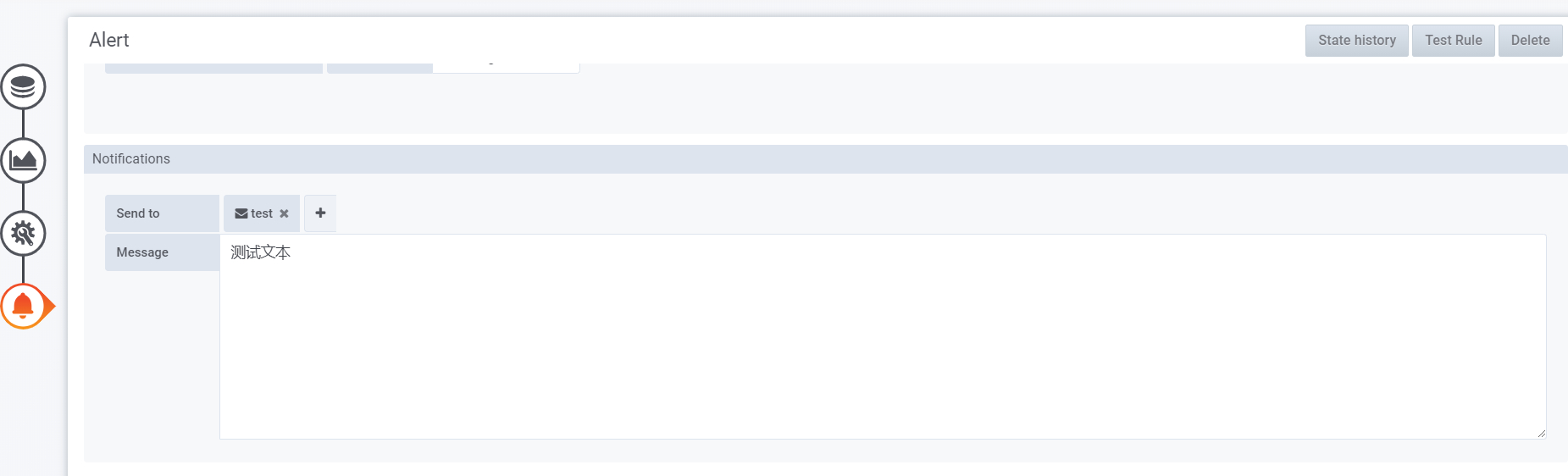
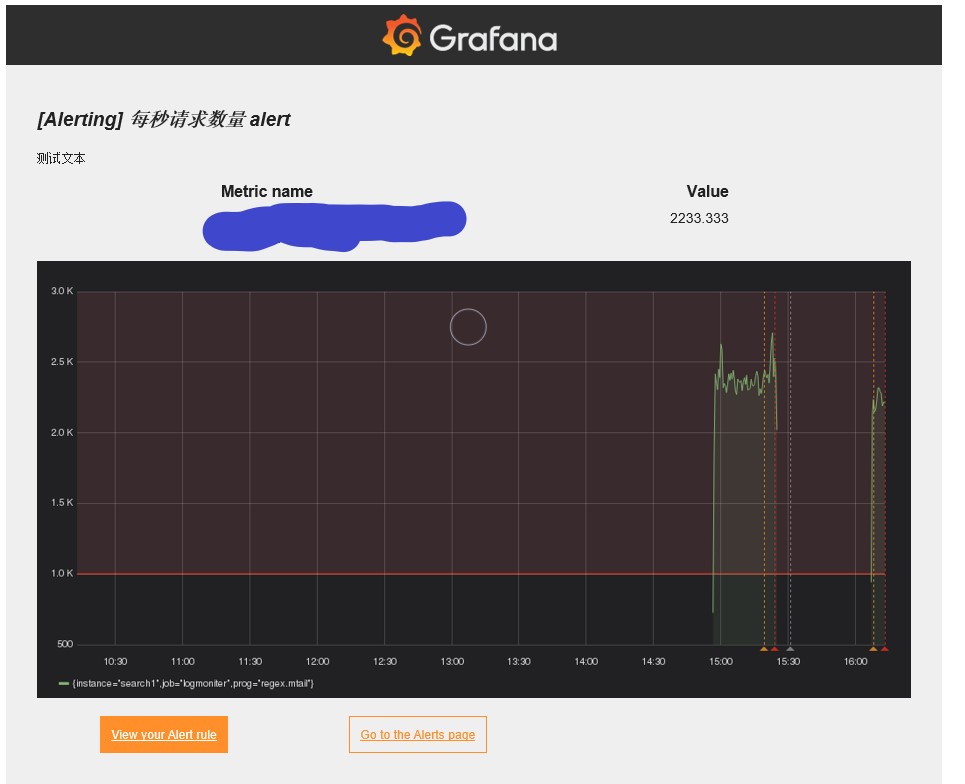
修改prometheus.yml配置文件,添加如下配置
1 2 3 4 5 6 7
$ vim prometheus.yml # Set remote read/write use local influxdb database remote_write: - url: "http://localhost:8086/api/v1/prom/write?db=prometheus"
Database names, measurements, tag keys, field keys, and tag values are stored only once and always as strings. Only field values and timestamps are stored per-point. Non-string values require approximately three bytes. String values require variable space as determined by string compression
mtail is a tool for extracting metrics from application logs to be exported into a timeseries database or timeseries calculator for alerting and dashboarding.
defusage(): Unit = { val usageMessage: String = """ | ./ConfigGenerator.scala -j <job_name> -p <port> -f <ip_list_file> [-L <label_name>=<label_string> ...] | | -j <job_name> | it will be generate to | " - job_name: 'machine_state'" | | -p <port> | target port for prometheus metrics | | -f <ip_list_file> | the file of all instance ip, one ip for one line | | -L <label_name>=<label_string> | this may contain multiple configuration item, such as | "-L env=test -L enable=on" | it will be generate to | env: "test" | enable: "on" | it should contain the same <label_name> twice |""".stripMargin println(usageMessage) sys.exit(1) }
defmain(args: Array[String]): Unit = { if (args.length == 0) usage() val argList = args.toList typeOptionMap= Map[Symbol, Any]
@scala.annotation.tailrec defnextOption(map : OptionMap, list: List[String]) : OptionMap = { list match { caseNil => map case"-j" :: value :: tail => nextOption(map ++ Map(Symbol("job") -> value.toString), tail) case"-p" :: value :: tail => nextOption(map ++ Map(Symbol("port") -> value.toString), tail) case"-f" :: value :: tail => nextOption(map ++ Map(Symbol("file") -> value.toString), tail) case"-L" :: value :: tail => if (value.split("=").length != 2) { println(s"'$value' is not a valid format") usage() } val labelName = value.split("=").head val labelText = value.split("=").last nextOption(map ++ Map(Symbol(labelName) -> labelText), tail) case option :: tail => println("Unknown option "+ option) sys.exit(1) } }
val defaultSymbols = Array(Symbol("job"), Symbol("port"), Symbol("file")) deftemplate(ipList: Array[String], optionMap: OptionMap): String = { val job = optionMap("job") val port = optionMap("port") val header = s""" | - job_name: '$job' | static_configs: |""".stripMargin
val labelKeyValues = optionMap.view.filterKeys(!defaultSymbols.contains(_)) val labelsConfigs = labelKeyValues.map(x => { val labelText = x._1.name val labelValue = x._2.toString s""" $labelText: "$labelValue"""".stripMargin }).mkString("\n")
val res = header + ipList.map(body).mkString("\n") + "\n" println(res) res }
val options = nextOption(Map(), argList) if (defaultSymbols.exists(!options.contains(_))) { println(s"need to set default config: ${defaultSymbols.map(_.name).mkString(",")}") usage() }
val ipFileHandle = scala.io.Source.fromFile(options("file").toString) template(ipFileHandle.getLines().toArray, options) } }