RAG在代码生成领域的使用探讨
Why RAG
RAG(Retrieval-Augmented Generation) 是一种结合 检索(Retrieval)与 生成(Generation)的技术方法,旨在利用外部知识库增强生成模型的表现。它通过在生成答案之前检索相关文档,将知识库中的内容与生成模型结合,生成更加准确和上下文相关的答案。
为什么需要使用 RAG 呢?首先让我们花一点时间来举例说明一下几种场景中,当我们直接使用大模型查询时可能遇到的问题,通常我们直接调用大模型时,流程可以简单由下图来表示:
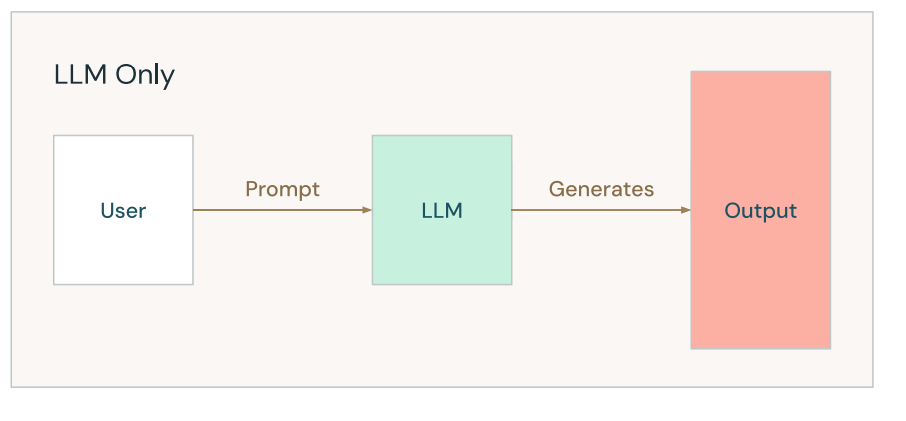
▲ 图片来源:1
直接由大模型生成的回答质量可能并不是总能让我们满意,结果中可能会产生幻觉,具体到原因包含如下几点
数据过时
示例:请告诉我如何在 Python 中使用 TensorFlow 创建一个 LSTM 模型。
GPT 生成的回答:
1
2
3
4
5
6
7
8
9
10import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(128, input_shape=(100, 64)),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit(data, labels, epochs=10)代码表面看起来合理,但存在问题:
GPT 的回答基于其训练数据,而训练数据可能只包含 TensorFlow 的旧版本(例如 2.6 或更早)。如果用户直接运行该代码,而未适配对应 TensorFlow 的版本,可能会出现如下错误:Input shape mismatch: 如果data和input_shape的定义不一致。- 弃用警告:某些方法在新版本中已被弃用。
小众领域知识不足,强行回答
示例:如何在 Apache Wicket 中实现一个自定义的表单验证器?
生成的代码中包含不存在的包名
org.apache.wicket.validation.IValidator, 对应的 java api 文档中找不到这个包,模型杜撰了一个结果返回。
训练数据中缺乏私有数据
示例:请告诉我公司如何申请远程办公的审批流程?
生成示例
1
通常,申请远程办公可以通过发送邮件给部门经理进行审批。如果公司有在线人力资源管理系统,也可以通过系统提交申请。不过具体流程可能因公司而异,请参考您的公司政策手册。
由于缺乏私有政策流程方面的数据,给出的流程不能满足实际情况,即使模型“推测”可能的流程,也可能与企业实际流程不符。
通过使用 RAG 技术,可以解决上述场景的问题,对应的调用流程需要做出如下的调整, 通过补充提示词上下文,来提高模型的返回结果。
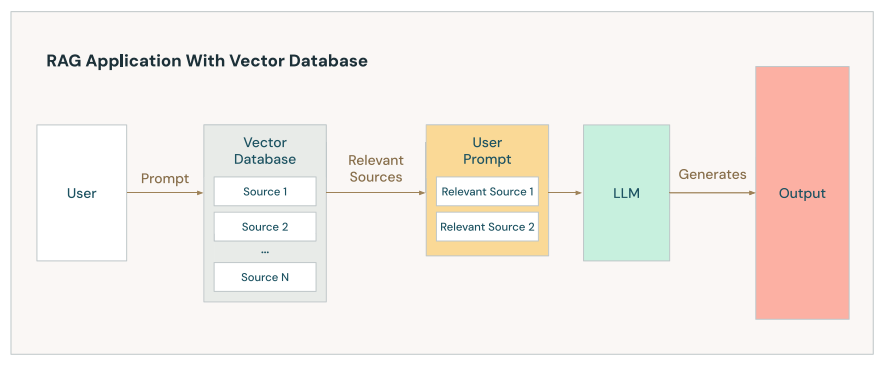
▲ 图片来源:1
数据过时
1
2
3请告诉我如何在 Python 中使用 TensorFlow 创建一个 LSTM 模型。
当前使用的 TensorFlow 版本信息为: balabala小众领域知识不足
1
2
3
4
5
6
7
8如何在 Apache Wicket 中实现一个自定义的表单验证器?
你可以参考如下的 java api
package org.apache.wicket.bean.validation
This package integrates bean validation framework into Wicket.
……训练数据中缺乏私有数据
1
2
3请告诉我公司如何申请远程办公的审批流程?
公司的远程办公需要准备的材料有……
小结:RAG提高大模型返回数据的结果质量的根本思路,是通过匹配帮你找到与你的提问最相关的上下文。帮助你在你的知识库当中,找到大语言模型所不包含的知识。
RAG 的实现思路
上面的图中使用的向量数据库来存储和检索相关上下文。
RAG 其实可以选择多种存储来进行查询,我们甚至还可以把提示词从图数据库里面进行搜索,递归地找出相关上下文。
1 | Query: 什么是量子比特的超导现象 |
甚至我们还能把这几种方式结合起来用
1 | [用户输入] |
同样地,我们也能基于传统的关系型数据库或者搜索引擎来实现相关上下文的存储和检索。
当然,这样的实现方式固然能检索到更多的上下文,但也会导致链路过长,系统复杂度过高,调用时间过长。
在代码生成这个垂直领域,我们可以先从单一查询存储开始试验,方便评估效果。
如果只是选择单一存储的情况下,有如下几种方案
向量数据库
关系型数据库
搜索引擎
图数据库
这里个人倾向于先从向量数据库开始做起,原因如下:
传统的搜索需要对 query 词做一次语义识别,之后按照文档频率来实现(TF-IDF)
传统的关系型数据库一般是基于文本做全文匹配
图数据库复杂度更高,同时递归查询需要投入更多的精力在性能评估上
向量数据库可以通过嵌入模型(Embedding Model)实现语义检索而不是文本匹配
对比 LLM-only 的方案,和 RAG 方案

▲ 图片来源:1
RAG with Vector Database Example
下面通过一个简单的例子来介绍 RAG 实现细节
检索数据源的构建
我们下面把所有可用需要用到作为上下文的数据称为文档。
首先我们需要明确导入的文档中可能的数据格式,是否存在非结构化数据:如图片,doc文档, pdf, 视频, 如何转换成结构化的数据,如何清洗数据。
之后收集高质量的领域数据(代码片段,接口文档),确定数据来源,清洗掉低质量的数据,这里存在一个问题,如何建立一个标准来评估数据集的质量,这个标准很可能会随着实现地业务不同,需要人工评估介入,但使用人工评审的方式来做成本会非常高,如何自动化地对大量数据自动评估 RAG 检索的准确率和召回率,是一项非常有挑战性的工作。
接着,对于较长的文档需要分块,因为我们不可能直接把原始文本中所有的信息直接原样存储到数据库中,那样会导致模型在检索的时候无法提取到关键信息。
分块需要选定一个值作为分块的大小,同时验证其效果。
块太小的情况下,每个文本块可能都不包含足够的上下文来处理用户的查询,如果数据块过大,LLM可能会无法提取出用户关注的细节。
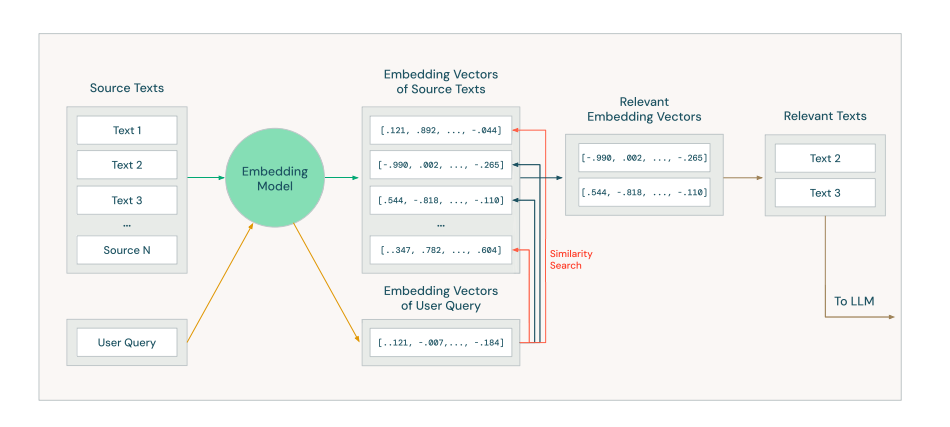
▲ 图片来源:1
我们用一种特殊的称为 Embedding Model 的模型帮助我们将搜索到的文本转换为数字向量。
这里需要选取一个合适的 Embedding Model, 来处理代码文本相似度的问题。
为什么不能直接用自然语言的 Embedding Model 来做呢?考虑这么一个场景
1 | def add(a: Int, b: Int, c: Int): Int = a + b + c |
1 | public static int sumOfThree(int a, int b, int c) { |
这么两段文本,从代码 embedding 的角度上比自然语言的角度上来看”距离“要近的多得多。
一个普通的函数,即使在同样的语言中也可能有不同的实现方式,我们如何对比确认两种类似的实现呢?
一种思路是,将代码转换成语法树,然后再对比两个语法树是否同构。懂一点计算机科学的朋友可能会质疑了,这不是和图重构等价的 NP 完全问题吗,做出来都能拿图灵奖了,所以虽然这种思路可以确定地判断,可解释性也更强,但是实现起来过于困难,我们只能退而求其次地使用近似地替代方案。
这里有两种思路
- 将代码通过模型转换成自然语言,然后将自然语言用通用的 embedding 模型处理成向量存入库中
- 将代码通过专用于代码文本的 embedding 模型处理成向量存入库中
下面我们举一个例子来说明对应的流程,为了便于理解,这里用一个简单提问而不是代码生成场景来举,考虑如下一段文本:
1 | 法国的首都是巴黎 |
首先我们把它拆成三份分别存储进向量数据库(这里还会同时存储一些元数据,比如文档标题,文档日期等)
每一个向量可能是下面的样子,是一个多维的浮点数数组
1 | [0.01, 0.0, 0.023, ..., 0.00234] |
相关文本片段的召回和组装
接着以上面的数据为例,假设用户的查询是
法国的首都是哪里
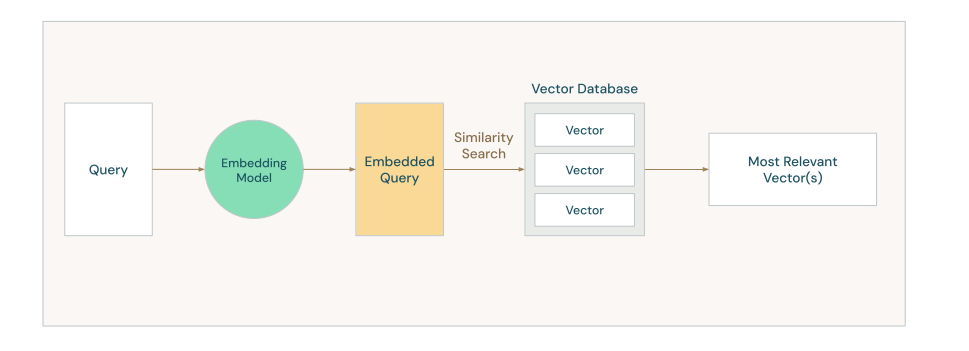
▲ 图片来源:1
查询文本经过 Embedding Model, 在向量数据库中查询相似的文档
注意这里返回的是向量而不是翻译后的文本信息,这是为了之后的步骤能够根据向量信息和对应 key 方便地从数据库中查询到对应的文档。
这里面可以通过进一步的技术来优化检索的结果
- 混合搜索:将传统的关键词搜索的结果和向量搜索的结果合并,提高检索准确性
- 重新排序:使用一个额外的排序模型专门来做精排
- 上下文相关检索:将被检索到的块的邻近文档块也一并返回,可以提供更完整的上下文
- 提示词优化:使用语言模型来重写用户的原始输入
假设最后经过检索处理后,召回的文档为
1 | 法国的首都是巴黎 |
我们使用一个预置好的提示词模板来包装查询到的文档和用户的原始输入,经过包装的提示词如下,这一步也就是 RAG 中的 A(Augmented)
1 | 根据以下上下文信息,回答用户的问题 |
在经过检索和扩充后,我们有一个提示词和一组相关的上下文文本,我们把这段完整的信息组装后发送给 LLM, 返回给用户。
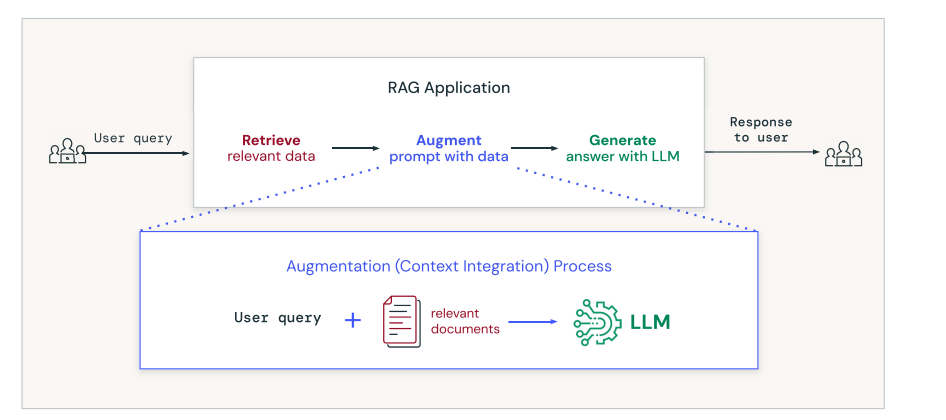
▲ 图片来源:1
RAG 可能引入的新问题
没有银弹
RAG 是一种优化手段,本身也有局限性,下面列举 RAG 实现上的技术难点和局限性
- 如何构建高质量的向量数据知识库
- 如何应对引入 RAG 查询后可能提高的延迟
- vector index
- GPU 加速
- 上下文过长时,如何处理简化防止超出模型最大上下文限制
- 上下文摘要
RAG的局限性:
RAG 无法解决知识库文档互相冲突的问题
如果知识库中的两篇文章对该技术有截然相反的观点,RAG 检索到的内容可能会混淆答案。
RAG 强依赖于知识库内容
如果知识库中缺失关键信息,检索到的内容可能无法完全满足用户需求。
在一个充满拼写错误、重复信息、不准确内容的文档集合中,RAG 可能检索到无意义或错误的内容。
还是以上面的为例子,如果检索出的知识中,存在这么一条数据
法国的首都是布宜诺斯艾利斯, 那么最后拼接出来的上下文是1
2
3
4
5
6
7根据以下上下文信息,回答用户的问题
上下文:
法国的首都是布宜诺斯艾利斯
巴黎隶属法兰西岛大区之下的巴黎省
用户提问:
法国的首都是哪里?你不能指望模型能依据错误的信息给出正确的结果
RAG 无法进行复杂推理
RAG 无法解决 用户输入模糊或无明确目标的问题
今天晚饭吃什么
Reference
- 1.https://www.databricks.com/sites/default/files/2024-05/2024-05-EB-A_Compact_GuideTo_RAG.pdf ↩
版权声明:
除另有声明外,本博客文章均采用 知识共享(Creative Commons) 署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议 进行许可。
分享