LLM 上下文压缩漫谈
AI 创作声明
本文使用的 Token 切分示意图,基于 Cursor + Claude 4.5 生成的应用程序调用 Gemini API 生成。
本文关于 LLM 上下文窗口图表的绘制借助了 Cursor + Claude 4.5 直接生成的 HTML 页面。
本文系亲自撰写, 文本内容经由 Cursor + Claude 4.5 润色。
在使用大语言模型(Large Language Model,以下简称 LLM)的过程中,无论你是 AI 工具的使用者还是开发者,都绕不开一个核心概念——Token。
本文将深入探讨 LLM 上下文压缩的常见实践方法。
Token 基础概念
上下文压缩的对象是传递给 LLM 的提示词,而理解提示词就必须先理解 Token 这个概念。
什么是 Token?
在 LLM 领域中,Token 是模型处理文本的最小单位。简单来说,LLM 本质上是一个概率统计模型,它根据之前的输入预测接下来最可能输出的文本,而 Token 就是构成这段文本的最小单元。
Token 的划分方式依赖于分词器(Tokenizer)。对于不同的输入语言,分词的实现方式各不相同。以下面这段文本为例:
1 | LLM 上下文压缩不简单 |
你可以将其输入到 OpenAI 官方提供的 Token 计算器中,可视化地查看分词效果和 Token 数量。
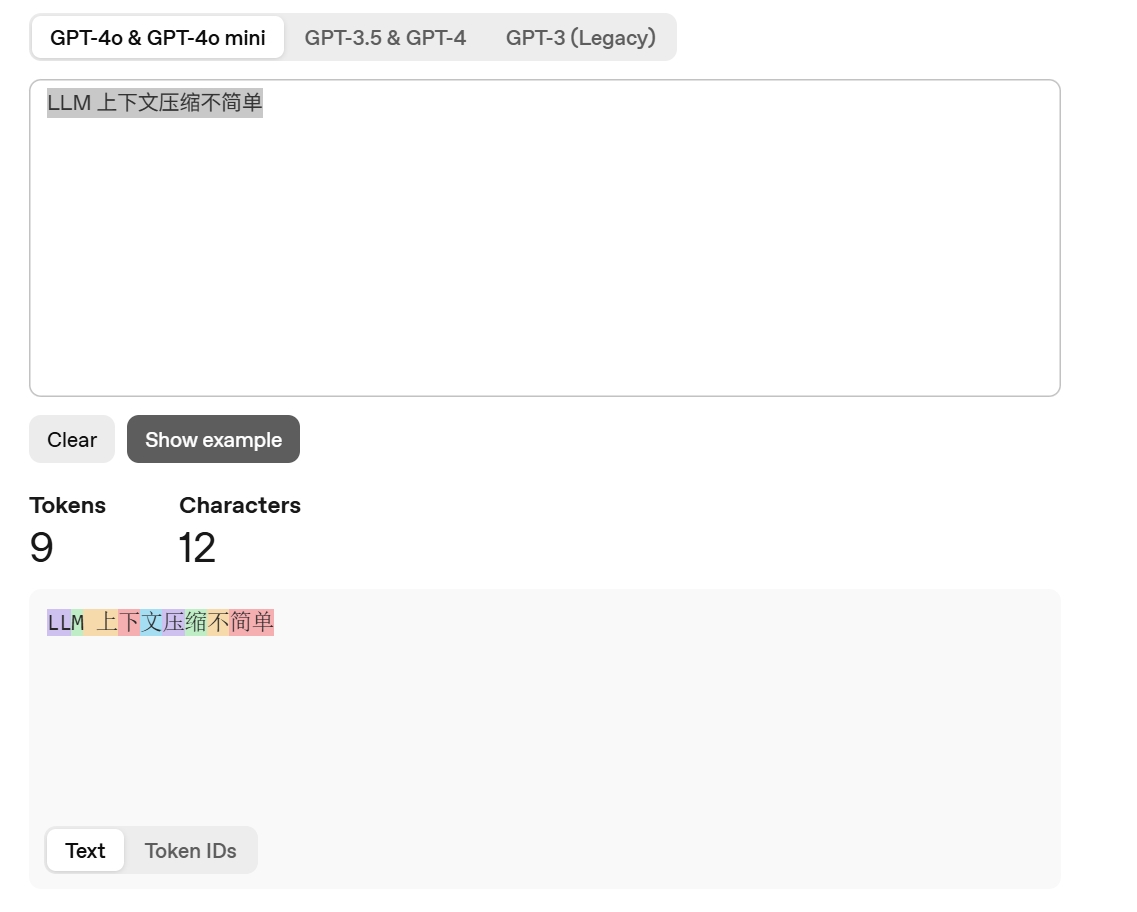
中英文 Token 消耗对比
有一个反直觉的现象:许多人认为相同信息的文本,中文消耗的 Token 数量更多。其实不然,这需要具体情况具体分析。
下面是上述文本翻译成英文后计算出的 Token 数量,可以看到二者相同。
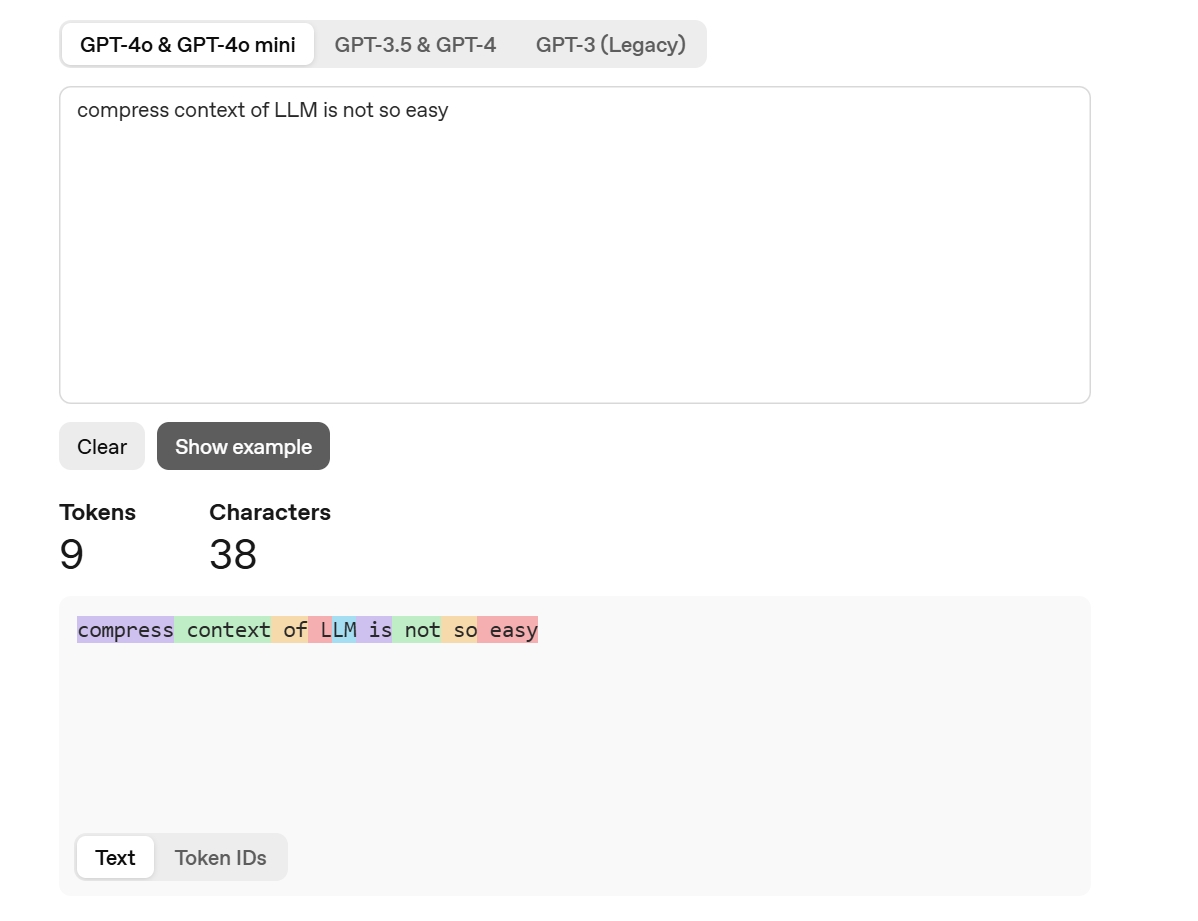
不同模型的分词差异
还有一点需要注意:由于不同型号 LLM 的分词机制存在差异,同一段文本在不同模型中对应的 Token 数量可能完全不同。
借助 Cursor,我实现了一个计算 Gemini Token 的单页应用。需要说明的是,Gemini API 只返回了 Token 数量,并未返回具体的分词方式,下图仅为示意效果。
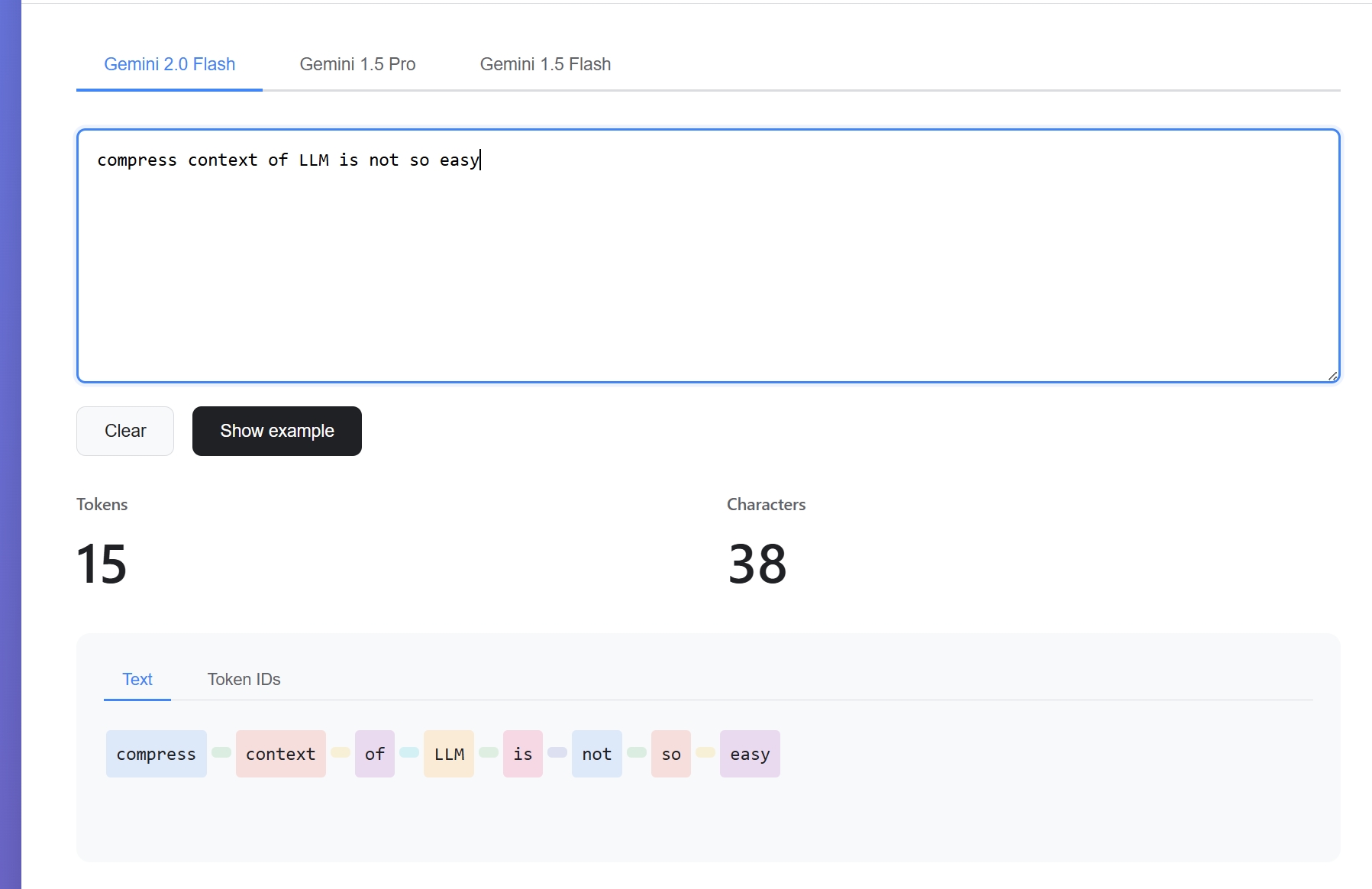
通过上述例子,我们可以得出以下结论:
- 不同模型的分词方式并不一致,即使是同一厂商的不同型号模型也可能存在差异
- 对于相同信息,中文和英文消耗的 Token 数量并无绝对的多少之分,需要根据具体模型和内容具体分析
Token 的标准化困境
换句话说,我们缺乏一个标准化的方式来评估不同模型的上下文窗口大小。对于应用开发者而言,如果要准确统计不同模型的 Token 消耗,需要投入大量成本进行适配。
一个真实的案例
让我们通过一个实际案例来理解 Token 容量的概念。在真实场景中,你可能会遇到客户反馈:”为什么我的模型调用失败了?”打开日志一看,发现了这样的错误信息:
1 | This model's maximum context length is 131072 tokens. However, you requested 132848 tokens in the messages, Please reduce the length of the message. |
131072 个 Token 到底有多大?
- 换算单位:128 KiB(Ki 是以 1024 为基数,k 是 1000)
- 对应文本大小:约等于一个 637.5 KiB 的 JSON 文件
- 内容量级:相当于 300-360 页小说
听起来容量不小,对吧?但实际上,模型为了理解你的请求,需要将整个对话历史都加载到上下文中。对于优化不佳的应用程序来说,这点上下文窗口远远不够:
- 读取一张高清图片可能就会耗尽上下文
- 反复读取一个几千行的代码文件,想要添加一个需求,就可能把上下文用光
这不是假设,而是我在实际工作中真实遇到过的问题。
上下文窗口的发展趋势
自 2022 年 12 月 ChatGPT 横空出世以来,大模型的上下文窗口经历了怎样的发展?在可预见的未来(1-3 年内),模型的上下文窗口是否会遵循类似芯片领域的”摩尔定律”?
让我们通过一些主流模型的上下文窗口规格参数来分析这个问题:
| 厂商 | 模型型号 | 发布时间 | 上下文窗口 |
|---|---|---|---|
| OpenAI | gpt-3.5-tubrbo-0125 | 2024-01-25 | 16385 |
| gpt-4o-2024-05-13 | 2024-05-13 | 128000 | |
| o1 | 2024-12-05 | 200000 | |
| GPT-5 | 2025-08-07 | 400000 | |
| gemini-2.0-flash-lite-001 | 2025-02-25 | 1048576 | |
| gemini-2.5-pro | 2025-05-09 | 1048576 | |
| Anthropic | claude-3-haiku-20240307 | 2024-03-07 | 200000 |
| claude-sonnet-4-20250514 | 2025-05-14 | 200000 | |
| claude-sonnet-4-5-20250929 | 2025-09-29 | 200000 | |
| DeepSeek | DeepSeek-V3 | 2024-12-26 | 128K |
| DeepSeek-R1 | 2025-01-20 | 128K | |
| DeepSeek-V3.2-Exp | 2025-09-29 | 128K | |
| 阿里巴巴 | qwen3-coder-plus | 2025-07-23 | 1000000 |
| qwen3-max | 2025-09-24 | 262144 | |
| 智谱 | GLM-4.6 | 2025-09-30 | 200K |
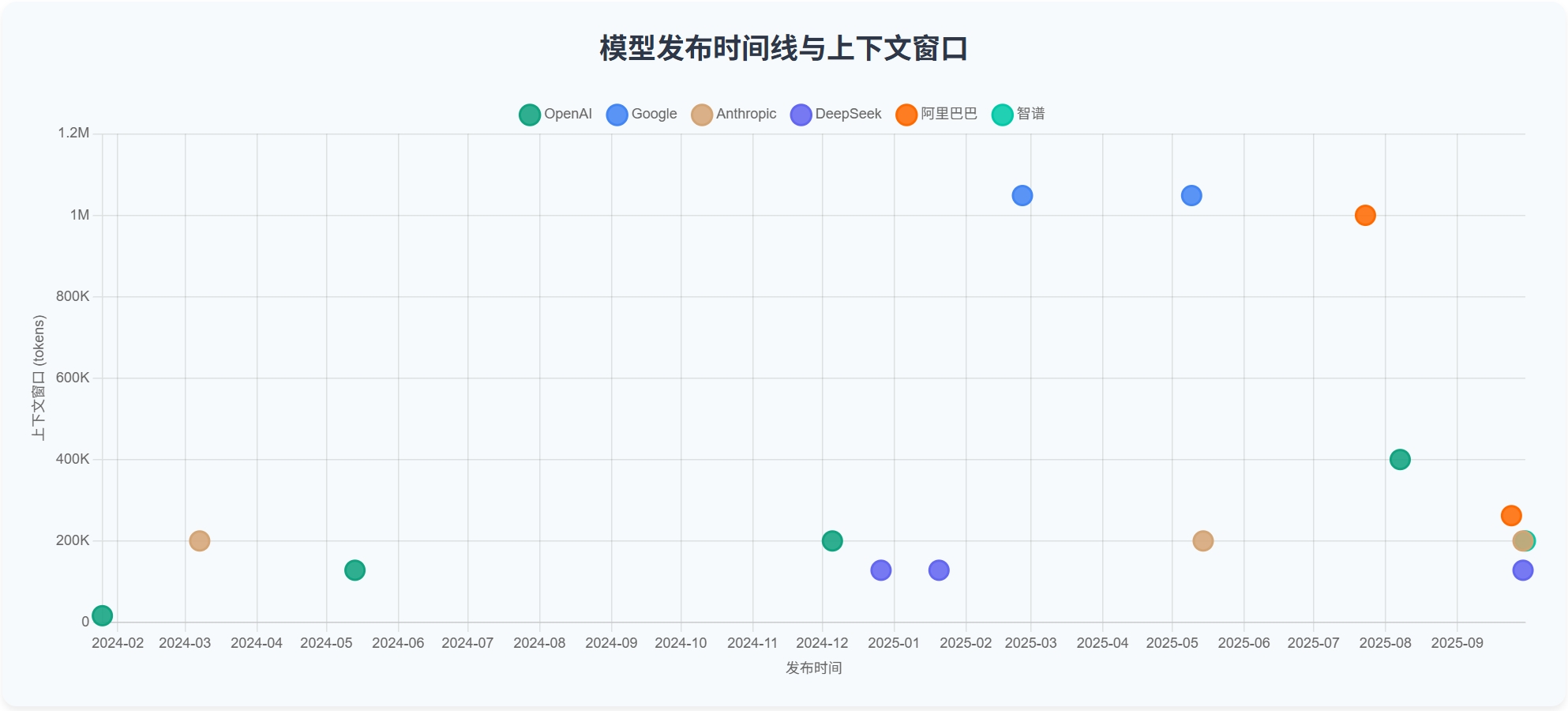
增长趋势分析
从图表中可以看出,在可预见的未来(3 年内),模型上下文窗口的增长并不会遵循类似”摩尔定律”的规律。
上下文窗口的增长并非强依赖于硬件性能的提升(尽管与显存容量密切相关),而是由算法和工程层面的突破驱动的。
技术瓶颈
计算复杂度:标准 Transformer 的注意力计算量为 O(n²),这意味着上下文窗口每增加一倍,所需的推理显存会呈平方级别增长。
缓存优化的局限:即使使用推理缓存将生成端计算近似降到 O(n),显存消耗仍然随 Token 长度线性增长。
长程对齐挑战:随着上下文窗口的增长,模型对长程文本的检索和对齐难度也会相应上升。
前缀缓存机制详解

▲ 图片来源:OpenAI 文档
前面提到,利用前缀缓存(Prompt Caching),我们可以将推理成本从 O(n²) 降低到 O(n)。这一机制与后续的上下文压缩密切相关,值得深入了解。
工作原理
前缀缓存的核心思想是:对相同的提示词进行哈希处理后,将其存储在内存中作为缓存。当新的提示词前缀与缓存中已有的结果完全匹配时,就可以直接复用,从而节省这一部分的计算量。
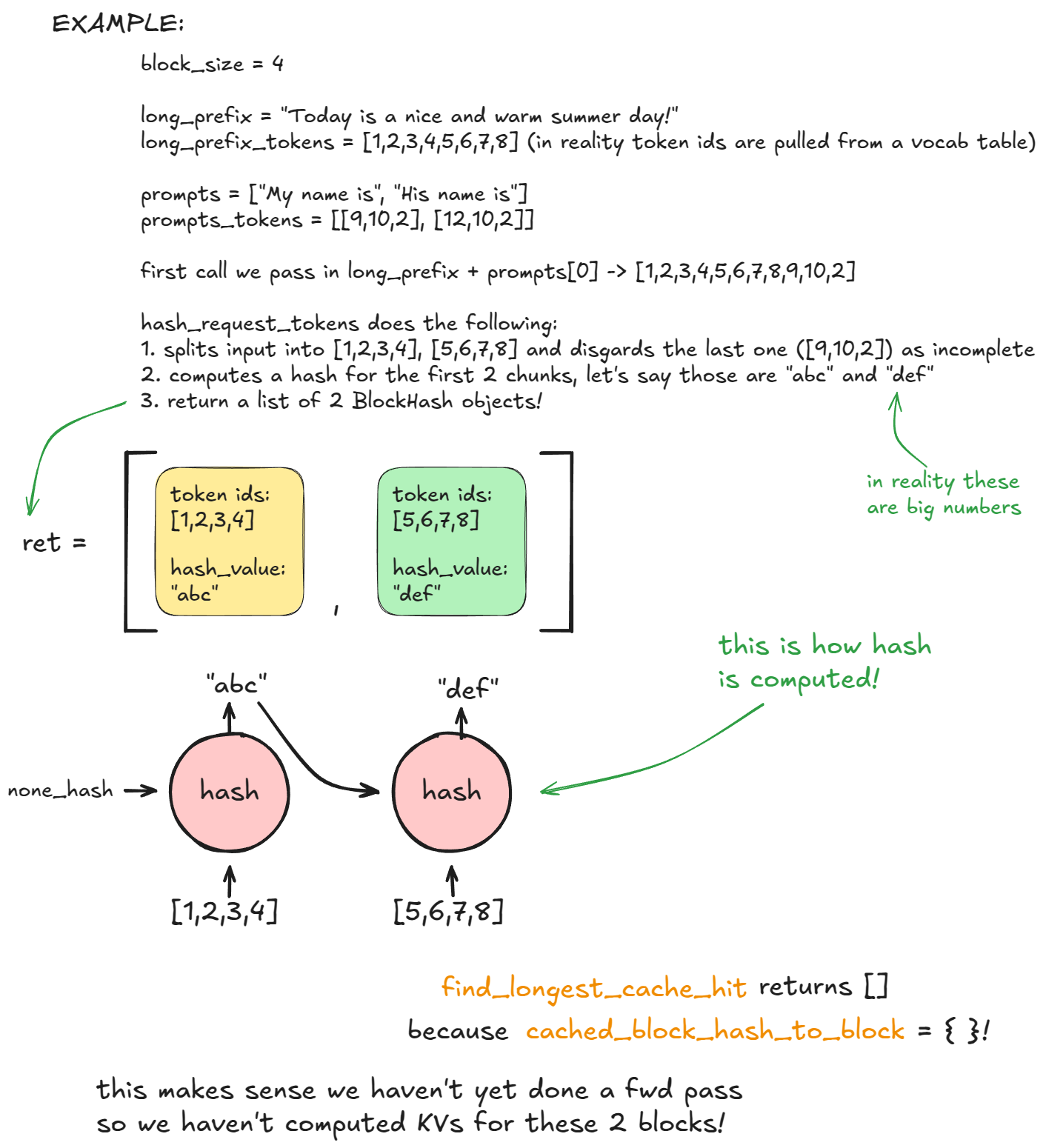
▲ 图片来源:vLLM Blog
感兴趣的读者可以参考 vllm 框架对于前缀缓存实现细节的文章
顺带一提,不正确地实现 prompt caching 可能会引发问题,不同的前缀令牌仍然有可能具有相同的哈希值。如果基于哈希实现的方式不当,可能出现冲突,导致错误地复用不匹配的缓存结果
比如实现用 MD5 直接对用户输入做哈希,那很可能导致不同用户的提示词错乱
客户端的不正确使用也会影响 cache 的使用,比如 oh-my-opencode 曾经不正确地往系统提示词里面添加了当前时间,导致缓存失效,token 消耗为原来的 5~10 倍
主流上下文压缩方案对比
通过前面的铺垫,我们了解了上下文压缩的必要性。在长对话场景中,随着历史记录的不断增长,最终会触及模型的上下文窗口限制。此时需要一种压缩方案,在尽可能保留关键语义的前提下,以较低成本达到良好的压缩效果。
两大压缩策略
上下文压缩通常有两种实现方式:
- 语义压缩:基于 LLM 的智能摘要
- 消息裁剪:基于规则的历史消息删减
需要注意的是,这两种方式都会不可避免地丢失部分原始信息。
典型产品分析
接下来,我们将深入分析以下三款主流 AI 编程工具的上下文压缩实现:
- Claude Code
- Roo Code
- Continue
Claude Code
Claude Code(以下简称 CC)是 Anthropic 开发的智能编程工具,运行在终端环境中。
分析说明
由于 CC 是闭源项目,本文的技术实现细节来自社区逆向工程的结果。
免责声明:
- 分析基于版本:Claude Code 1.0.33
- 分析方法:使用 CC 自我分析
- 可能存在的偏差来源:
- 模型幻觉导致的理解偏差
- 版本更新带来的实现变化
核心机制
CC 使用基于 LLM 的语义压缩来处理对话历史,目标是在不丢失关键信息的前提下,大幅减少对话长度,从而节省 Token 消耗,保障长对话的流畅性。
压缩本质:将 N 条历史记录压缩成 1 条助手消息。
触发方式:
- 自动压缩
- 手动压缩
提示词设计
CC 的压缩提示词经过精心设计,要求 AI 助手创建详细的对话摘要,重点保留以下信息:
- 技术细节
- 代码模式
- 架构决策
提示词采用 One-shot 方式,提供了一个压缩输出结果的示例,并要求在 XML 标签内输出分析整理过程。
参考资源:
自动压缩
触发时机:在任务执行前进行预检,当对话历史的上下文占比超过阈值(约 94%)时,后台自动触发压缩流程。
处理流程:
- 压缩完成后,多条历史消息合并为一条
- 记录统计信息(原始长度、压缩后长度)
- 如果压缩失败,自动降级到原始消息
用户体验流程:
1 | 用户输入: "帮我优化这个 React 组件的性能" |
手动压缩
触发方式:通过 /compact 命令手动触发。
特色功能:支持自定义压缩偏好,用户可以通过参数指定保留的信息类型。
示例:保留调试过程和错误信息
1 | compact Emphasize the debugging process, error messages encountered, and the step-by-step solutions implemented. |
与自动压缩的区别:
- 不涉及 Token 使用率阈值检测
- 支持用户自定义压缩提示词
- 其他步骤与自动压缩基本一致
Roo Code
Roo Code 是从开源项目 Cline fork 的一个分支,由于其开源特性,我们可以直接从源码入手进行分析。
版本说明:以下分析基于版本 3.25.8
核心策略
Roo Code 采用双重压缩机制:
- 主策略:基于 LLM 的智能摘要生成
- 兜底策略:滑动窗口机制
LLM 摘要
源码参考:sliding-window/index.ts#L145-L166
1 | if (autoCondenseContext) { |
触发条件(满足任一即可):
- 百分比触发:上下文占比 ≥ 设定阈值
- 绝对值触发:Token 数量 > 允许上限
消息预处理机制:
- 模型兼容性检查:检测模型是否支持图片
- 图片内容转换:将图片块替换为文本描述
"[Referenced image in conversation]" - 结构保持:保持消息的其他结构不变
压缩策略:
- 安全检查:确保至少有 2 条消息可供压缩(第一条消息总是会被保留)
- 压缩范围:对对话的”中间部分”进行压缩
消息重组结构:
1 | // 新的消息序列 |
参考资源:
滑动窗口
使用场景:
- 未开启自动压缩且 Token 超过比例限制
- 自动压缩失败需要兜底方案
实现方式:基于规则的消息裁剪(非 LLM)
源码参考:sliding-window/index.ts#L41
1 | export function truncateConversation(messages: ApiMessage[], fracToRemove: number, taskId: string): ApiMessage[] { |
裁剪示例:
原始消息队列:[1, 2, 3, 4, 5, 6, 7]
移除比例:50%
裁剪结果:[1, 4, 5, 6, 7]
两种策略对比
| 特性 | 滑动窗口 | 智能压缩(LLM) |
|---|---|---|
| 处理速度 | 极快(毫秒级) | 较慢(需要 LLM 调用) |
| 实现复杂度 | 简单 | 复杂 |
| 内容保留 | 机械式保留最近内容 | 智能提取关键信息 |
| 成本 | 零成本 | 有 API 调用成本 |
| 可靠性 | 100% 可靠 | 可能失败 |
| 上下文质量 | 可能丢失重要的中间信息 | 保留结构化的关键信息 |
| 角色交替 | 通过偶数截断保证 | 通过消息重组保证 |
Continue
Continue 是支持 JetBrains 和 VS Code 的开源代码助手插件。
核心策略
Continue 采用双重处理方式:
- 手动触发:基于 LLM 的对话摘要
- 自动处理:基于规则的消息裁剪
LLM 摘要
触发方式:用户通过 GUI 手动点击压缩按钮

压缩效果:
- 历史会话在前端显示为灰色
- 出现明显的分割线
- 后续会话会将对话摘要作为系统提示词的一部分传入模型
压缩逻辑流程:
1 | 1. 消息预处理 |
参考资源:Continue 压缩提示词
消息裁剪
核心准则:
- 始终保留最后的用户/工具消息序列(包括带有工具调用的助手消息)
- 始终保留系统消息和工具信息
- 不允许出现没有对应工具调用的孤立工具响应
- 优先移除较旧的消息
- 通过合并相邻的相似消息保持对话连贯性
标准处理流程:
- 对于不支持图片的模型,先处理图片内容的转换
- 提取并保留系统消息
- 过滤掉空消息以及末尾非用户/工具的消息
- 从末尾提取完整的工具调用序列(用户消息或助手 + 工具响应)
- 计算不可删除元素(系统消息、工具、最后消息序列)所需的 Token 数
- 裁剪较旧的消息,直到满足可用 Token 限制
- 按正确顺序重新组装消息,并合并相邻的相似消息
实际请求构建流程:
1 | 1. 查找最近的对话摘要 |
三款工具的压缩方案对比
| 对比维度 | Claude Code | Roo Code | Continue |
|---|---|---|---|
| 触发方式 | • 自动:Token 使用率 > ~94% • 手动: /compact 命令,支持定制提示词 |
• 自动:基于百分比或绝对数量 • 被动:压缩失败时滑动窗口 |
• 手动:GUI 按钮触发摘要 • 自动:每次请求前规则裁剪 |
| 实现方式 | 基于 LLM 的语义压缩 将 N 条历史合并为 1 条助手消息 |
双重机制: LLM 摘要 + 滑动窗口兜底 |
双层机制: 手动摘要 + 自动 Token 级裁剪 |
| 保留策略 | • 保留系统消息和工具 • 保留最后的用户/工具序列 • 不允许孤立工具响应 |
• 保留第一条消息 • 保留最后 N 条消息 • 图片转文本 |
• 保留系统消息和工具 • 保留最后的用户/工具序列 • 合并相邻同类消息 |
| 兜底机制 | 压缩失败使用原始消息 (可能超限) |
滑动窗口: 按比例删除偶数条消息 |
降级到自动裁剪 超限严重则报错 |
| 消息预处理 | 未明确基于规则的裁剪 | • 图片替换 • 摘要去重 • 压缩检测 |
• 图片转文本 • 空消息过滤 • 工具序列抽取 • 同类消息合并 |
| 性能 | 较慢(LLM 调用) | LLM 摘要:较慢 滑动窗口:极快 |
LLM 摘要:较慢 自动裁剪:极快 |
| 实现复杂度 | 高(闭源,逆向分析) | 中(开源,逻辑清晰) | 高(双层实现,规则复杂) |
| 上下文质量 | 高 保留结构化关键信息 |
中高 摘要质量高,窗口可能丢失关键信息 |
高 摘要 + 精细化裁剪 |
| 成本 | 中(频繁 LLM 调用) | 低-中(优先 LLM,兜底零成本) | 低(手动触发为主) |
| 用户控制度 | 中(支持自定义提示词) | 低(配置项有限) | 高(手动触发,可见压缩边界) |
总结与最佳实践
上下文压缩的本质
上下文压缩之所以必要,根本原因在于 LLM 是无状态服务:
- **”短期记忆”**:将对话历史全部加载到上下文窗口中
- **”长期记忆”**:将上下文存储到外部存储(如
Claude.md文件,或以向量形式存放到知识库)
主流压缩策略
当前业界的上下文压缩方式主要分为两大类:
- 语义压缩:通过 LLM 智能总结历史对话
- 规则裁剪:通过预定义规则对历史消息进行删减
核心挑战
1. 信息损失不可避免
必须认识到:无论采用哪种压缩方式,都会不可避免地丢失部分原始信息,无法做到真正的无损压缩。
“这个问题是根本性的:Agent 本质上必须根据所有先前状态预测下一个动作——而你无法可靠地预测哪个观察结果可能在十步之后变得至关重要。从逻辑角度看,任何不可逆的压缩都带有风险。”
—— Manus 团队《Context Engineering for AI Agents》
2. Token 计算的模型依赖性
上下文压缩的触发时机通常基于 Token 数量评估,但这存在一个问题:
- 不同模型的分词方式各不相同
- 准确计算 Token 需要针对每个模型单独实现
- 增加了开发和维护成本
3. 与前缀缓存的冲突
引入上下文压缩后,可能无法充分利用模型的前缀缓存机制:
- 成本影响:以 Claude 为例,不使用缓存的调用成本是使用缓存的 10 倍
- 工程权衡:部分模型厂商提供显式缓存设置接口,需要在工程层面权衡
“现有 Agentic Coding(包括 Devin AI、SWE-agent、OpenHands 等)本质上都是基于 LLM Orchestration 规则构建的’脚手架’。这些人为设计的上下文裁剪规则、多轮对话管理策略,本质上是在用工程手段弥补模型能力的不足。更讽刺的是,这类设计往往与底层模型的 KV-cache 机制存在冲突——当开发者通过裁剪历史对话来节省 token 消耗时,实际上破坏了 transformer 架构最宝贵的前缀缓存优势,在 DeepSeek 等支持动态缓存的模型上反而可能导致计算资源浪费。”
—— 杨博,知乎回答
语义压缩的实践建议
基于 LLM 的语义压缩方式大同小异,关键在于针对业务场景微调系统提示词:
- 明确指定需要保留的信息类型(技术细节、错误信息、决策过程等)
- 使用 One-shot 或 Few-shot 示例提高压缩质量
- 在 XML 或结构化标签中输出分析过程,便于调试
规则裁剪的最佳实践
基于规则的消息裁剪应遵循以下原则:
1. 保留关键消息
首条消息优先保留:用户的第一条消息通常包含原始需求,具有重要的上下文价值。
2. 兜底方案而非主策略
按比例粗暴丢弃不应作为通用裁剪方式,但可以作为可靠的兜底方案(如 Roo Code 的滑动窗口)。
3. 内容选择性保留
禁止二进制内容:
- 二进制数据会耗尽上下文且对模型无意义
- 必须在上下文构建时过滤
大段文本的处理:
- 避免直接加载大文件到上下文
- 优先传递文件路径或 URL
- 让模型按需通过工具分段读取,确保数据实时性
保留失败记录:
- LLM 会产生幻觉,工具会返回错误,边缘情况随时发生
- 失败是多步骤任务循环的一部分,而非例外
- 常见误区:隐藏错误、清理痕迹、依赖”温度”参数重试
- 正确做法:保留失败记录,让模型从错误中学习,降低重复错误的概率
维护结构完整性:
- 用户消息与助手响应必须成对
- 工具调用与工具返回必须对应
- 不允许孤立的工具响应
场景化优先级:
- 对于编程场景:优先保留错误信息、调试日志
- 对于写作场景:优先保留创作思路、修改建议
- 根据具体业务定制保留策略
未来展望
上下文压缩本质上是用工程手段弥补模型能力不足的权宜之计。
回顾 LLM 发展史:
- 早期需要”Let’s think step by step”这样的粗糙 CoT 提示
- 甚至出现过”你必须 XXX 否则我就把你断电”的威胁式提示
- 这些技巧随着模型能力提升已逐渐弱化
上下文压缩是否也会随着模型进化而变得不再必要?亦或会演变出新的解决方案?
犹未可知。
参考资料
GitHub - RooCodeInc/Roo-Code: Roo Code gives you a whole dev team of AI agents in your code editor.
Inside vLLM: Anatomy of a High-Throughput LLM Inference System
致谢:感谢开源社区对 AI 编程工具的持续贡献,以及各位研究者的深入分析和实践经验分享。
版权声明:
除另有声明外,本博客文章均采用 知识共享(Creative Commons) 署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议 进行许可。
分享