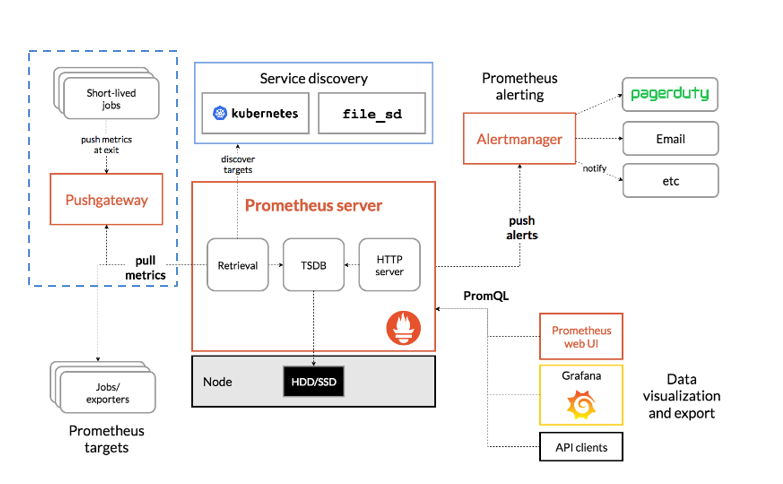
# my global config global: scrape_interval:15s# Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval:15s# Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml"
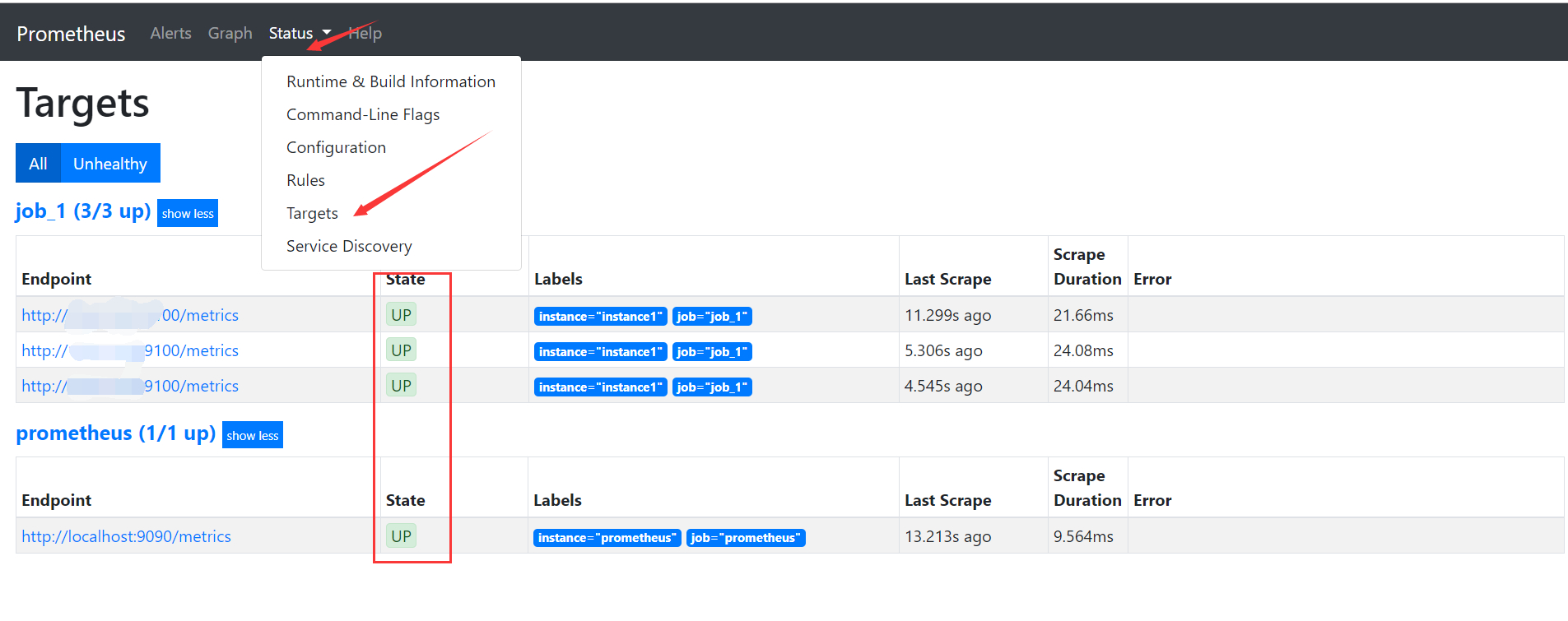
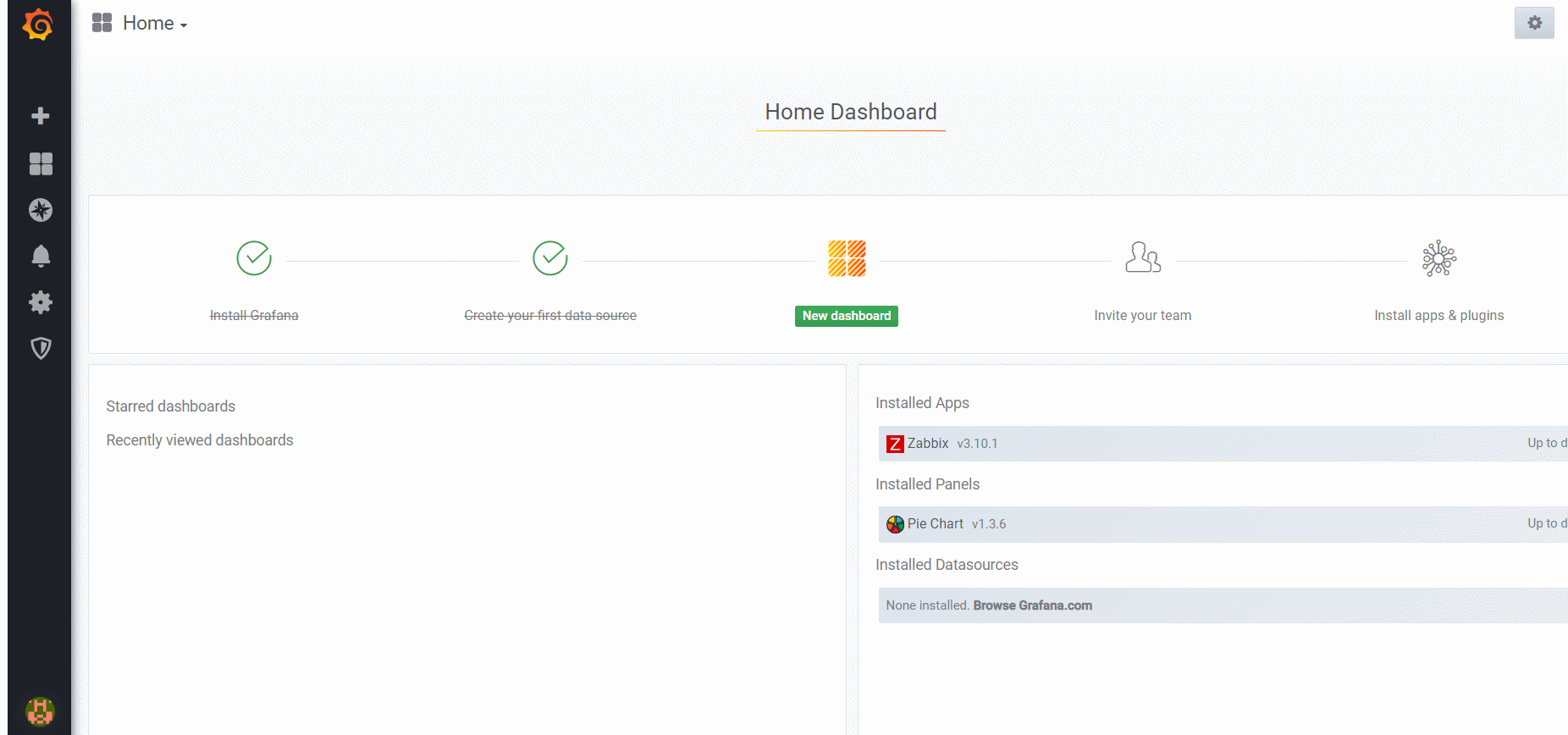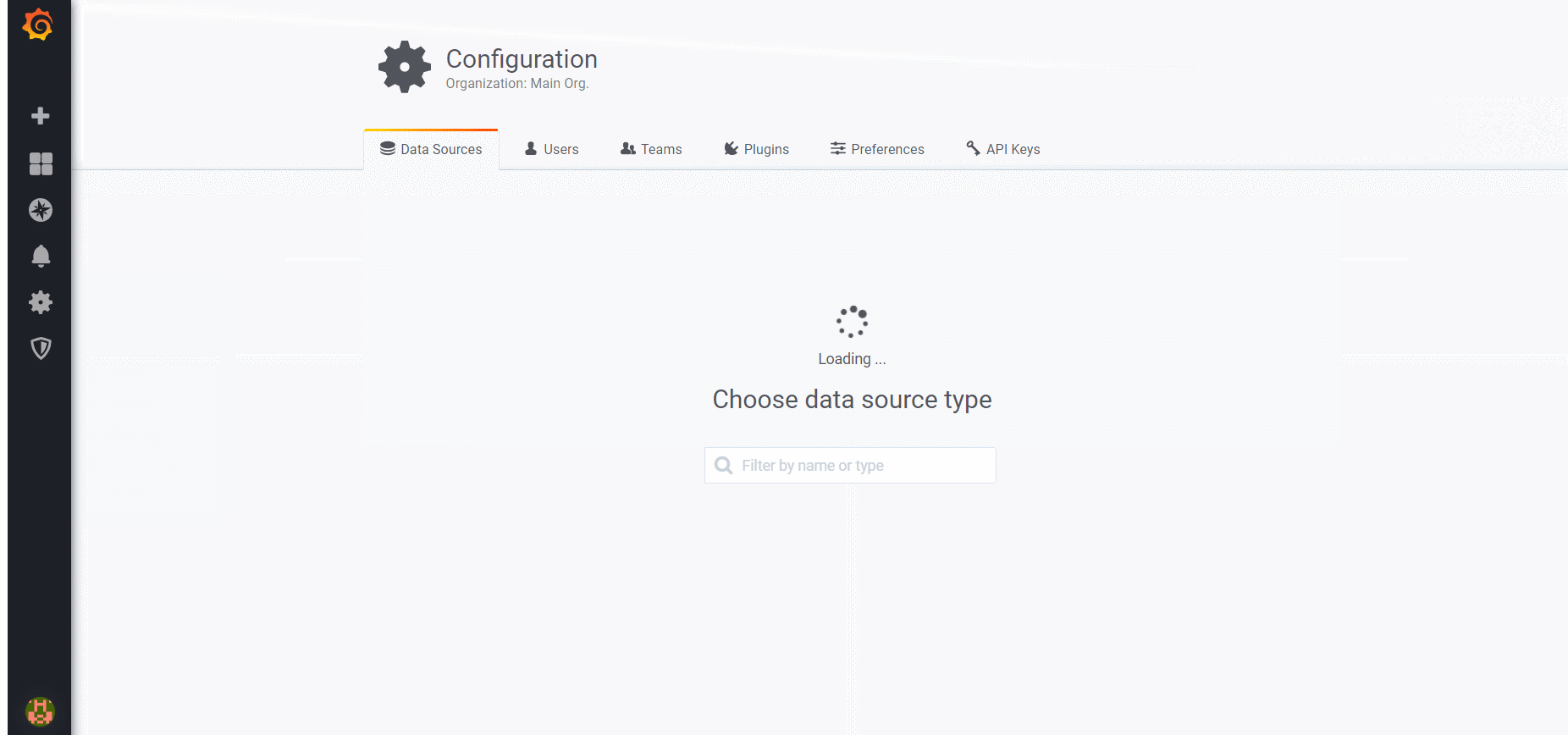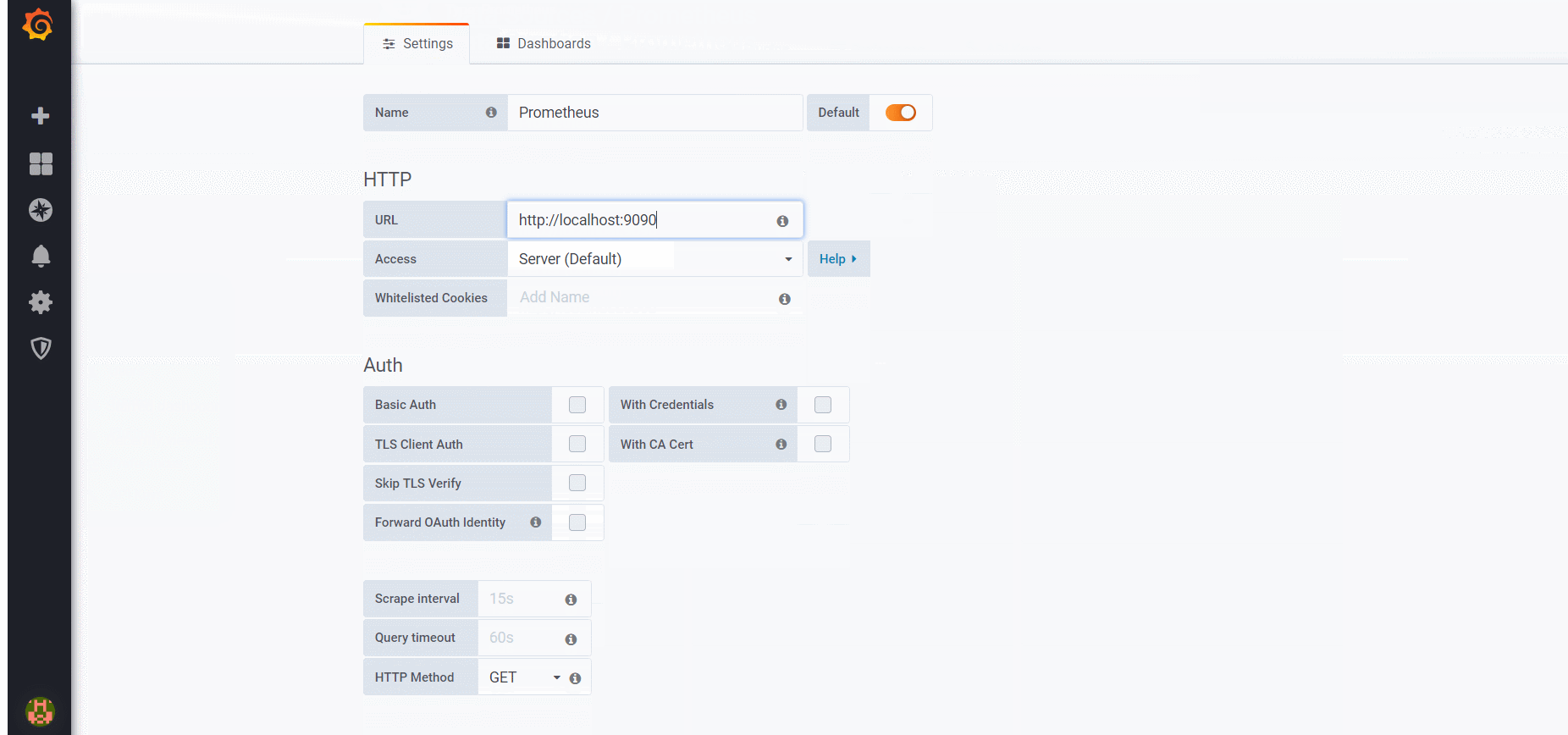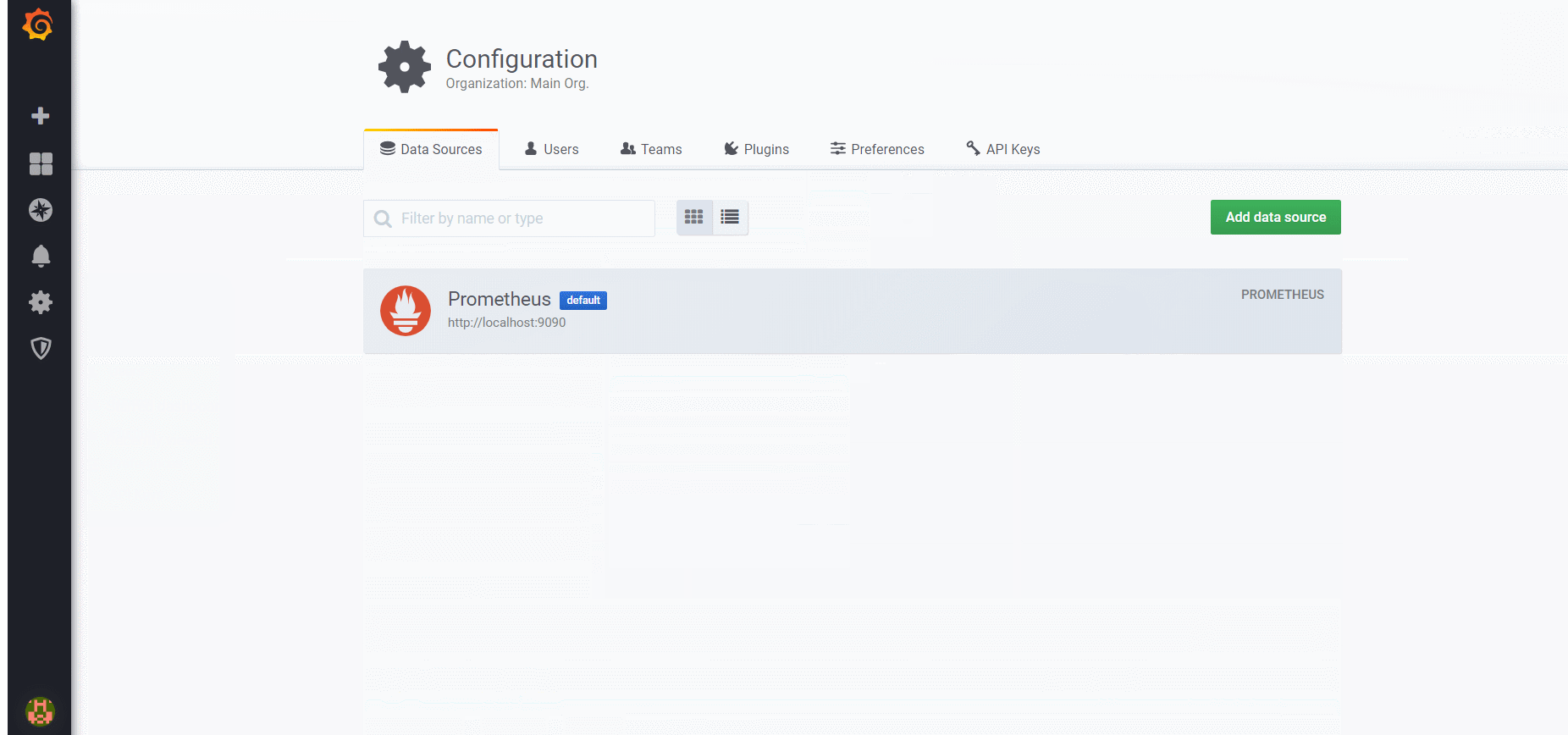
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# metrics_path defaults to '/metrics' # scheme defaults to 'http'.
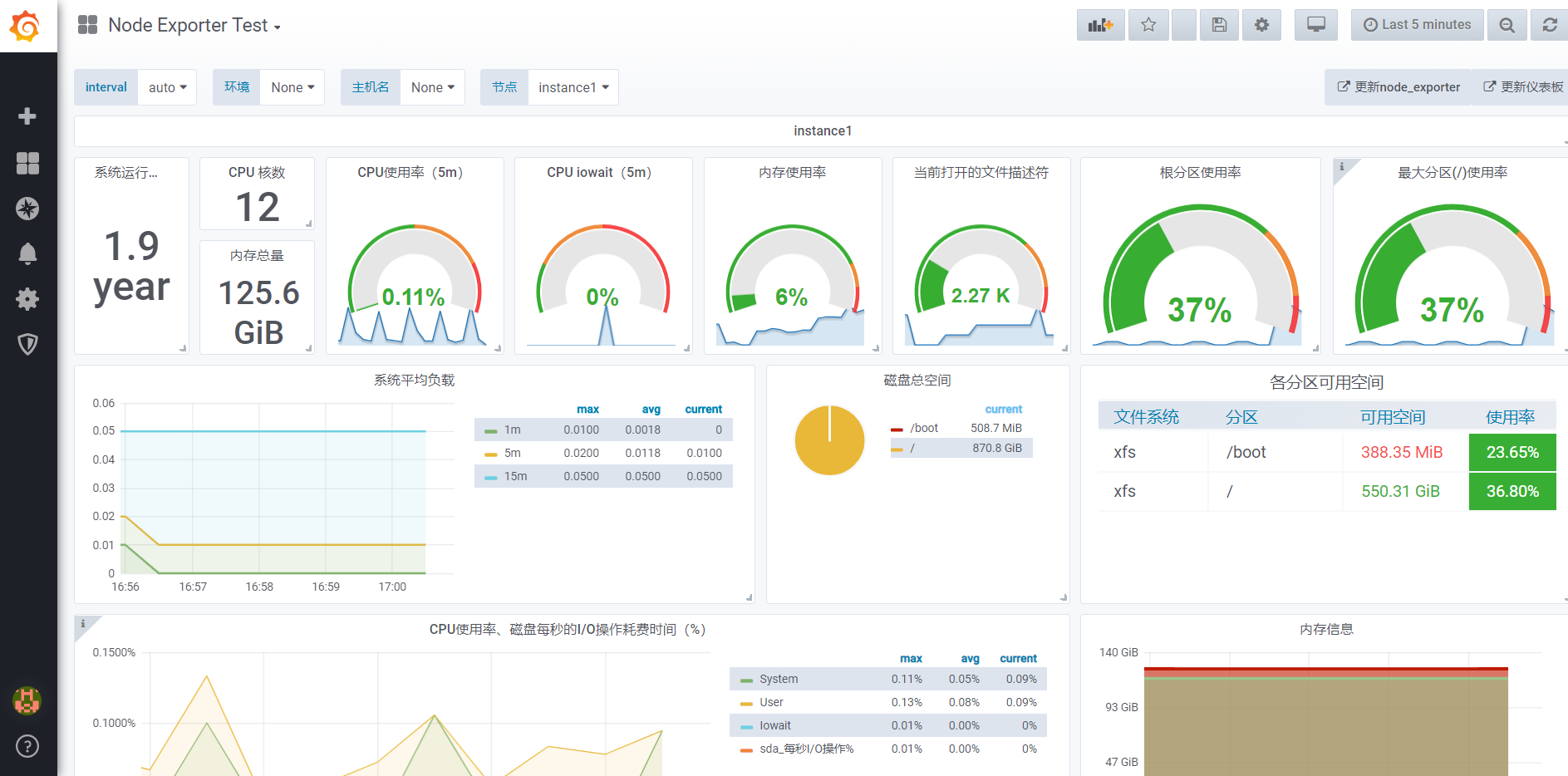
#################################### SMTP / Emailing ########################## [smtp] enabled = true host = localhost:25 ;user = # If the password contains # or ; you have to wrap it with trippel quotes. Ex """#password;""" ;password = ;cert_file = ;key_file = skip_verify = false from_address = [email protected] ;from_name = Grafana # EHLO identity in SMTP dialog (defaults to instance_name) ;ehlo_identity = dashboard.example.com
[emails] welcome_email_on_sign_up = true
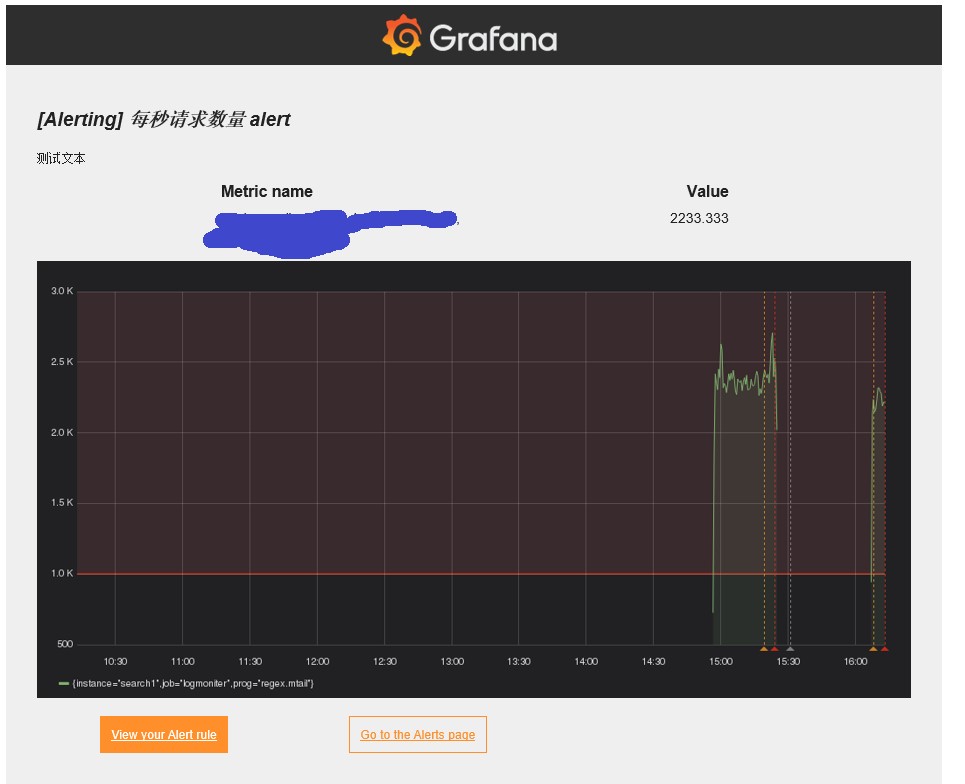
#################################### Distributed tracing ############ [tracing.jaeger] # Enable by setting the address sending traces to jaeger (ex localhost:6831) ;address = localhost:6831 # Tag that will always be included in when creating new spans. ex (tag1:value1,tag2:value2) ;domain = localhost
# Redirect to correct domain if host header does not match domain # Prevents DNS rebinding attacks ;enforce_domain = false
# The full public facing url you use in browser, used for redirects and emails # If you use reverse proxy and sub path specify full url (with sub path) root_url = http://192.168.1.1:3000
funcmain() { //This section will start the HTTP server and expose //any metrics on the /metrics endpoint. http.Handle("/metrics", promhttp.Handler()) log.Info("Beginning to serve on port :8080") log.Fatal(http.ListenAndServe(":8080", nil)) }
$ curl localhost:8080/metrics # HELP go_gc_duration_seconds A summary of the GC invocation durations. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 0 go_gc_duration_seconds{quantile="0.25"} 0 go_gc_duration_seconds{quantile="0.5"} 0 go_gc_duration_seconds{quantile="0.75"} 0 go_gc_duration_seconds{quantile="1"} 0 go_gc_duration_seconds_sum 0 go_gc_duration_seconds_count 0 # HELP go_goroutines Number of goroutines that currently exist. # TYPE go_goroutines gauge go_goroutines 6 ... ... ... # HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code. # TYPE promhttp_metric_handler_requests_total counter promhttp_metric_handler_requests_total{code="200"} 0 promhttp_metric_handler_requests_total{code="500"} 0 promhttp_metric_handler_requests_total{code="503"} 0
//Define the metrics we wish to expose var fooMetric = prometheus.NewGauge(prometheus.GaugeOpts{ Name: "foo_metric", Help: "Shows whether a foo has occurred in our cluster"})
var barMetric = prometheus.NewGauge(prometheus.GaugeOpts{ Name: "bar_metric", Help: "Shows whether a bar has occurred in our cluster"})
funcinit() { //Register metrics with prometheus prometheus.MustRegister(fooMetric) prometheus.MustRegister(barMetric)
$ curl localhost:8080/metrics # HELP bar_metric Shows whether a bar has occurred in our cluster # TYPE bar_metric gauge bar_metric 1 # HELP foo_metric Shows whether a foo has occurred in our cluster # TYPE foo_metric gauge foo_metric 0 ... ... ...
# 另启动一个窗口,观察结果 $ cd ~/dev/mtail $ curl http://localhost:3903/metrics | grep line_count # HELP line_count defined at linecounter.mtail:3:9-18 # TYPE line_count counter line_count{prog="linecounter.mtail"} 0 # HELP mtail_line_count number of lines received by the program loader # TYPE mtail_line_count untyped
# 当往日志中新加入文本中时 $ echo "test1" >> test.log $ curl http://localhost:3903/metrics | grep line_count # HELP line_count defined at linecounter.mtail:3:9-18 # TYPE line_count counter line_count{prog="linecounter.mtail"} 1 # HELP mtail_line_count number of lines received by the program loader # TYPE mtail_line_count untyped mtail_line_count 1