Progfun 6. Collections
6.1 Other Collections
这一小节没有练习
Vector的数据结构是一个32叉树,这是一个更加中庸的集合
这样访问的过程可以看成近似一个常数,因为log_32(N)
| N | log_32(N) |
|---|---|
| 10 | 0.46 |
| 1000 | 1.38 |
| 100000 | 2.30 |
| 10000000 | 3.22 |
我们看到,N扩大100倍,对应的log_32(N)才大约增加1
另外一方面,对于每一Vector可以分治成32个更小的节点,这正好和现代缓存的大小接近(或许2020年来说是64更好一些?),这样每一个都能充分例用到缓存,更加迅速。
一般来说,如果操作偏向于递归,那么List更适合;如果操作是批量的,比如map/fold/filter,那么Vector更快。
另外提一句,在2.13.2有神人使用了新的数据结构来重构Vector
这PR提得简直和范文一样,啧啧啧,比如这个图

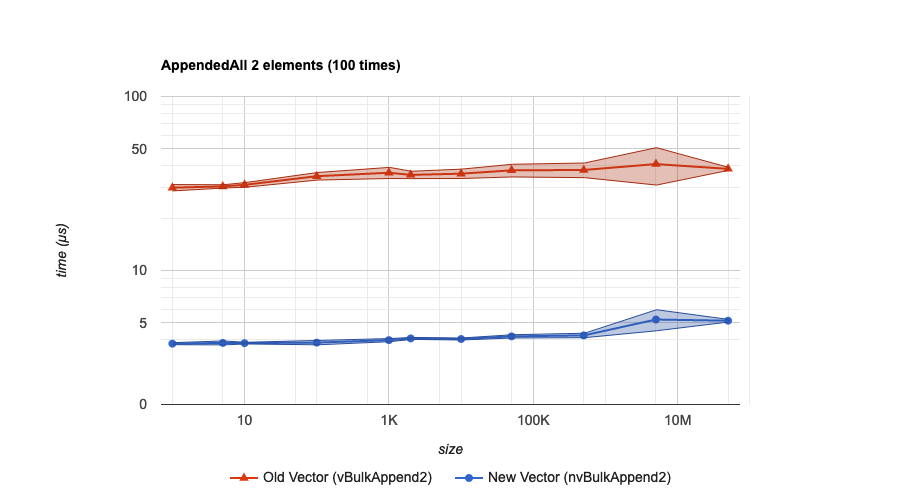
据说使用到的新数据结构叫做radix-balanced finger tree
相关论文有空看看 立了个Flag
- https://infoscience.epfl.ch/record/169879/files/RMTrees.pdf
- http://www.staff.city.ac.uk/~ross/papers/FingerTree.html
- http://comonad.com/reader/wp-content/uploads/2010/04/Finger-Trees.pdf
6.2 Combinatorial Search and For-Expressions
考虑一个这样的问题
给出两个数组A,B,找出两个数组中对于 j < i, A_i + B_j为素数的所有(i, j)
1 | val a = Array(2,3,4,4,5,6,6) |
6.3 Combinatorial Search Example
经典的N皇后问题
1 | def queens(n: Int): Set[List[(Int, Int)]] = { |
6.4 Maps
此map非彼map,为集合类里的map<key, value>
Martin写了一个用map来实现多项式结构的例子
1 | class Poly (terms0: Map[Int, Double]) { |
这里的习题是使用foldLeft版本来实现+方法,对应的函数签名如下
1 | def +(other: Poly) = new Poly((other.terms foldLeft ???)(addTerm)) |
实现如下
1 | class Poly (terms0: Map[Int, Double]) { |
对比这两个实现,哪一个性能更好呢?Martin认为foldLeft版本的更快,
从addTerm和adjust来看第一个用的语句更少,但实际上却是后者更快
这是因为两者的调用方式不同
1 | def +(other: Poly) = new Poly(terms ++ (other.terms map adjust)) |
So, I would argue the one with foldLeft is more efficient because what happens
here is that each of these bindings will be immediately added to our terms Maps so,
we build up the result directly, whereas before,
we would create another list of terms that contain the adjusted terms and
then we would concatenate this list to the original one.
前者会把terms做map操作,新生成的临时map再和原来的做连接,而后者省去了中间生成的步骤
口说无凭,我们来上测试
这里用的是sbt-jmh插件
简单的使用可以参看这篇文章
随便写了点测试代码,测试环境为
- Scala 2.13.2
- sbt 1.13.10
为什么包名叫abc呢,不放包里会报NPE错误,但是我又不擅长起名字
相关issue: https://github.com/ktoso/sbt-jmh/issues/134
1 | package abc |
测试依赖的代码
1 | package abc |
跑的过程中风扇狂转,IDEA跑的结果还有乱码,改到wsl开sbt跑
测试结果如下
1 | sbt > jmh:run -i 3 -wi 3 -f3 -t2 .*mytest.* |
差距还是挺明显的,也验证了之前的说法。
6.5 Putting the Pieces Together
以下的例子来源于
Lutz Prechelt: An Empirical Comparison of Seven Programming Languages. IEEE Computer 33(10): 23-29 (2000)
标题说的七种语言分别是
- TCL
- Python
- Perl
- Rexx
- Java
- C++
- C
对于上述语言编写这个例子所需要的代码行数
- 脚本语言:100行
- 其他语言:200 ~ 300 行
这一小节结合之前的内容,实现一个简单的程序,把电话号码(九键字母)转换成单词

假设我们有了这么一个字典
1 | val mnemonics = Map( |
设计一个函数如translate(phoneNumber),输出可以拼写出来的单词
如translate("7225247386")的输出结果中应该包括Scala is fun
除了给出对应的字典外,当然还给出了单词表
1 | val in = Source.fromURL("http://lamp.epfl.ch/files/content/sites/lamp/files/teaching/progfun/linuxwords") |
不幸的是,这个网址已经失效了
好在还能通过后面的编程作业Anagrams拿到同名文件linuxwords
给出的模板 代码如下
1 | import scala.io.Source |
有了样板,填空还是很容易的
1 | import scala.io.{BufferedSource, Source} |
简单说下思路吧
首先从当前目录的linuxwords.txt读取我们需要的单词表,这个文件可以在后面的作业中的src/main/resources/forcomp/linuxwords.txt找到,每行一个单词,大约有4万行。
读取进来后做一个简单的过滤,因为码表中只能映射字母,所以要过滤掉包含非字母的单词。
1 | scala> words.filter(s => s.exists(ch => !ch |
mnem作为映射表,就硬编码了,但是对应的倒排表不应该再次硬编码,这里简单的复用了下
1 | val charCode: Map[Char, Char] = { |
拿出k,v,对于v迭代,每个字母作为新的k’, 原来的k作为v’,构造(k’ -> v’)的map
如果你在 exercism.io 上刷题,你会发现这个步骤和ETL的题面非常相似
下面wordCode函数,将字符转换成大写后,调用map函数,传入的参数为Map(是不是像绕口令)
前面的map是变换操作,类似于filter,后面的Map是一个collection,类似于List
举个例子
1 | scala> val m = Map(1 -> 2) withDefaultValue 3 |
wordsForNum是把一个数字输入的字符串,映射成所有的合法单词序列的集合
encode巧妙地使用了for,从外到内依次为
- 遍历分割点
- 对于分割点之前的输入序列,能构成的所有单词集合进行遍历
- 对剩余部分递归的求出结果
将递归求出的结果和分割点前半部分的结果连接,作为一个合法的输出,把所有的输出收集起来,再转换成我们需要的Set格式
把上述代码在REPL中运行的结果如下
1 | scala> import scala.io.{BufferedSource, Source} |
和上面提到的七种语言对比,Scala的行数是最少的,只用了50行。
编程作业:Anagrams
作业下载地址:http://alaska.epfl.ch/~dockermoocs/progfun1/forcomp.zip
anagram (异序词)是把单词重新排列后得到的新的单词,比如
对于句子 I love you 可以改写成You I love的异序词,也可以改写成You olive
显然,这里是不区分大小写的
现在需要写出一个函数
1 | type Word = String |
能输出一个句子的所有异序词转换方案
这个问题其实就是上一个问题的变种,照猫画虎就行了。
核心代码
1 | def sentenceAnagrams(sentence: Sentence): List[Sentence] = { |
这个做法有一个问题,就是我们总是在不停地重复计算已经知道的结果,如果有办法保存下来就好了
那么如何来做持久化呢?
参考以下文章,我简单粗暴地改造了下
- https://medium.com/musings-on-functional-programming/scala-optimizing-expensive-functions-with-memoization-c05b781ae826
- https://stackoverflow.com/questions/16257378/is-there-a-generic-way-to-memoize-in-scala
1 | def sentenceAnagrams(sentence: Sentence): List[Sentence] = { |
这就不跑jmh了,电脑实在是吃不消
总结
之前的文章
- Progfun 1.Getting Start
- Progfun 2.High Order Fuctions
- Progfun 3.Data and Abstration
- Progfun 4. Types and Pattern Matching
- Progfun 5. Lists
终于写完了第一个系列的笔记,说实话这个其实老早就把作业写完了,但是有些不懂的地方,所以看了第二遍
其实第二遍还有些没懂的,比如泛型的协变逆变不变为什么要这样设计
年末就要发Scala 3了,这算是先把系统学习Scala 2的坑填了。
Martin讲课优点是非常适合新手,不是直接给你一个完整的解决方案,而是向你展示一段段代码是按什么样的思路写出来的,并且不断的进行重构,同时还会演示常见的出错场景和如何解决。
作业的习题难度,习惯后也还好,因为有完善的函数签名和注释,写起来就像做填空题一样
Martin讲课有个缺点就是,完全的平铺直叙,语调不带变的无情的朗读机器
字幕有时候会打错,稍微有点影响理解,不过课程整体感觉还是挺好的,我会给85/100的分
What’s more?
- FP(Functional Programming) design
- FP and state
- 并行编程和分布式系统
- Spark
版权声明:
除另有声明外,本博客文章均采用 知识共享(Creative Commons) 署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议 进行许可。
分享